通过以下 Referral 链接购买 DigitalOcean 主机,你将可以帮助 V2EX 持续发展
› DigitalOcean - SSD Cloud Servers

这是一个创建于 454 天前的主题,其中的信息可能已经有所发展或是发生改变。
大家好,我是雷池 WAF 社区版的开发者。
请先允许我打个广告:雷池 WAF - 全球领先的 Web 安全防护产品
前几天在公司群里聊天,大家表示最近逛国内的很多技术论坛( segmentfault 、oschina 、gitee 等等)都能看到雷池 WAF 的人机验证页面。
听到这个首先是非常荣幸,这说明雷池 WAF 得到了国内顶尖技术群体的认可。然后我们就在猜会不会是 AI 的崛起带来了爬虫的横行。
ChatGPT 的发布为技术工作者提供了很多便利,我自己日常也会通过豆包和 kimi 咨询很多技术问题,虽然 AI 回答的挺好,但是给我的答案大部分也来于各种技术论坛,典型的 ”拿你的数据,抢你的流量“。

和几个做技术社区的朋友交流了一番以后,证实了我们的想法。
“原先就被爬,AI 起来以后,防不胜防,爬的更狠了”——某位大论坛的 CEO 如是说。
传统的反爬虫
一般来说,在网站根目录下放一个 robots.txt 文件,可以用于告知爬虫哪些链接可以爬,哪些链接不能爬,然而 99% 的爬虫都不会遵守 robots 协议。
最高人民检察院在 2022 年就发布了对于网络爬虫的相关处罚条例,然而还是有很多恶意爬虫逍遥法外。
除了管理规范以外,技术上一般会用以下方式来防止网站被爬:
- 检查 User-Agent,封禁常见爬虫的 User-Agent 特征
- 检查 Referer,封禁不合法的 Referer 特征
- 限制访问频率,对访问超过限制的 IP 实施封禁
- 检查 Cookie,给认证过的合法用户颁发 Cookie ,阻断 Cookie 不合法的用户
- JS 动态渲染,关键术语使用 JS 加密后动态生成
传统反爬虫的无奈
针对以上讲到的传统反爬虫方式,其实有很多破解方案,可以轻易逃过检测:
- 检查 User-Agent:对于这种方式,直接在客户端伪造 HTTP 请求头即可绕过
- 检查 Referer:对于这种方式,直接在客户端伪造 HTTP 请求头即可绕过
- 限制访问频率:对于这种方式,可以使用代理池来获得大量源 IP ,每个 IP 实际访问量都不高
- 检查 Cookie:对于这种方式,可以让先人工获得 Cookie ,再把 Cookie 拿给爬虫使用
- JS 动态渲染:对于这种方式,调用无头浏览器即可绕过
高阶的反爬虫思路
- 请求签名:绑定客户端和 SESSION ,随意修改 IP 、User-Agent 、浏览器指纹等信息后 SESSION 自动吊销
- 识别行为:检测鼠标键盘的使用习惯,检测浏览器窗口的拜访位置,综合判断是不是真人行为
- 识别无头浏览器:识别本地浏览器的客户端特征,禁止无头浏览器访问
- 识别自动化调用:识别本地浏览器是不是被自动化程序控制,禁止自动化控制的浏览器访问
- 交互识别:让用户参与网页交互验证码,比如滑动验证、识别图片、识别文字等
- 算力验证:注入算力验证脚本,消耗 CPU 资源,抬高客户端的访问成本,让原本每秒可以访问 1000 次的设备,在被雷池保护后每秒只能访问 1 次
- 防止请求重放:增加一次性验证,让 HTTP 请求脱离浏览器后无法重复发送,让复制后的 Cookie 失效
- 打乱 HTML 结构:对 HTML 代码结构进行动态打乱,让爬虫无法识别网页特征
- 混淆 JS 代码:对 JS 代码进行动态混淆,让攻击者无法识别有效的网页逻辑
怎么用雷池防爬虫
雷池 WAF 包含了市面上绝大部分的反爬虫技术,而且可以免费使用。
关于怎么安装雷池,请参考官网的 技术文档
安装好雷池 WAF 以后开启防爬虫相关的功能即可生效,如下图:
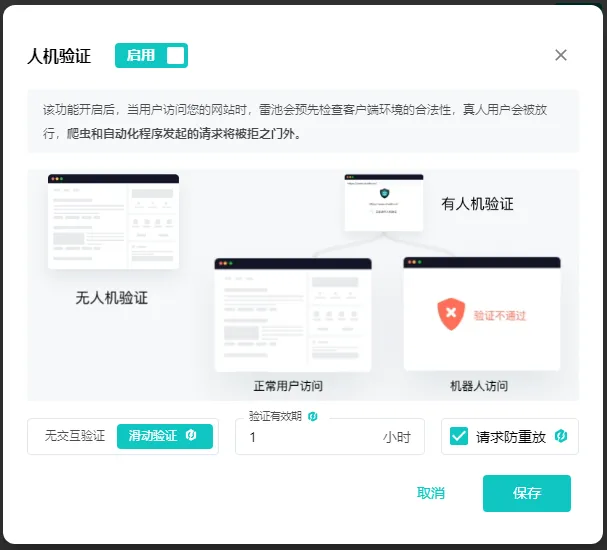

不出意外的话,1 分钟就能完成配置。完成配置以后,访问被雷池 WAF 防护的网站,就会看到雷池正在检查客户端环境的安全性。

合法用户等待两三秒以后真正的网页内容会自动载入,恶意用户则会被阻拦。
如果检测到本地客户端被自动化程序控制,访问依然会被阻止,如下图:

验证通过后查看网页源代码,会发现 HTML 和 JS 代码也都做了动态加密保护,虽然是相同的网页,但每次刷新看到的 HTML 代码结构都不同。
看一个例子,服务端的 HTML 文件如下图:

经过雷池动态防护以后,浏览器里看到的 HTML 文件如下图:

这里要说一下,雷池的人机识别是采用的是云端验证方式,每一次验证都会调用长亭的云端 API 来辅助验证,结合长亭的 IP 威胁画像数据,浏览器指纹数据,最终对于爬虫的**识别率超过 99.9%**。于此同时,云端的算法和 JS 逻辑会持续自动更新,即使被厉害的大佬破解,破解的也只是过去的版本,我们永远跑在攻击者的前面。
另外,如果有人能绕过雷池的人机验证,欢迎来长亭办公室找我,我请你吃一个月的 KFC。
看着这么高的识别率,网站站长们肯定会担心这会不会影响 SEO,会不会影响搜索引擎对于网站页面的收录情况。
答案当然是 “不会”,雷池贴心的提供了各大搜索引擎的爬虫 IP 列表,如果对 SEO 有需求,只需要对这些 IP 加白即可。

 |
1
phx1 2024 年 11 月 13 日
所以在哪测试呢?我想吃一个月的 KFC
是这个产品么? https://rivers.chaitin.cn/product/co2hvtla60nc73dirk3g?rc=T2UH73WKYIOOK5LIHUEDNJUI6LCAJFQW |