 推荐学习书目
› Python Cookbook
推荐学习书目
› Python Cookbook
最近将自己的一个小 app 迁移到了 GAE,说说感想和经验。
geeklian · 2015-06-21 10:54:34 +08:00 · 11182 次点击这是一个创建于 3756 天前的主题,其中的信息可能已经有所发展或是发生改变。
先说说感想
心里只有一万个WTF,一万个草泥马。
GAE的Datastore收费方法简直令人恶心,一个App的开发过程中,想着怎么优化write/read Op,浪费的时间和精力,你定可以转换为很多创新点子...特别是对于一个不存在code review的个人App来说。
如果app自用且足够小,放到GAE上追求个稳定,还是可以接受的,但理由也仅限如此了...
当初冲动的原因
本来是一个py3+Django写的小程序,跑在我的Linode JP VPS上。在优化扶墙的过程中,想将debian8换成debian7,然后想想为了未来省事,感觉把几个app移到gae上去吧,以后折腾vps也无所谓了。
软件成品在此,实现也很简单,每五分钟抓一些feed,然后jieba分词,然后推送消息...已经超免费配额了,大家随便看看就好,我不是职业写代码的,也就不敢开源出来献丑了。
坑和填坑
免费的GAE配额,以及一些坑
CPU:600 Mhz, 内存:128 MB, 28个执行小时。
- 占用过多的cpu和内存,会导致你的程序跑不满24小时就额度用尽。
- 当CPU占用高时,GAE会再起新Instance来应对新的请求,多个Instance多倍扣CPU时间。
- 当内存超限时,app可能直接被stop,不会死掉。
- 这对于jieba分词简直是灾难,在不修改代码的情况下,jieba初始化时就内存超限了,并且初始化词库需要高达12秒。
5万次数据库读作业,5万次写作业。
- 大坑!这里要特别注意索引,可能倍翻你的配额用量。
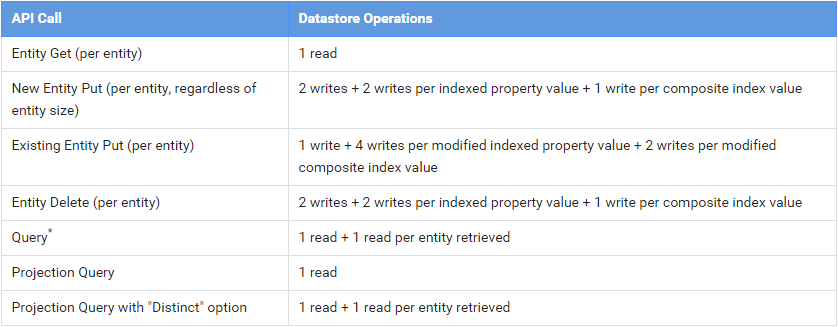
- 大坑!这里要特别注意索引,可能倍翻你的配额用量。
不支持Python3:处理中文,要花费大量时间在utf-8上。
不支持tempfile:很多库需要改造。
免费配额不支持socket:无法使用外部数据库。收费配额皆不可socket listen。
相比之下,其他的配额对应用的影响微不足道:Memcache是免费的。UrlFetch除非抓来的数据不做任何处理,Mail除非用来滥发邮件。
NDB配额优化
GAE的数据库额度存在3个关键:
- 激活账单后,Small Op目前是免费的不限量的,
keys_only=True可以随便用。 - get()和get_multi()查询会被自动memcache。
- indexed会倍增write Op
提取单条数据,使用get_by_key_name(),而不是fetch(1) / first()
user = User.query(User.username = "tom").first()
替换为
user = User.get_by_key_name("tom")
原方法会消耗1 Fetch Op + 1 Query Op = 2 read Op,修改后,会产生1 Small Op + 1 read Op,而且这个read Op会被自动memcache。
提取多条数据时,使用keys_only + get_multi()
比如一个表有,我想一次取出N条数据时,常规ORM的写法:
feeds = Feed.query().fetch(N)
每次查询,都会消耗1+N Read Op,为了优化额度,可以修改成:
q = Feed.query()
feeds = ndb.get_multi(q.fetch(N,keys_only=True))
首次查询,消耗1 Small Op + N Read Op,但是在重复查询是,则只消耗1 Small Op + m*N Read Op,m是memcache未命中的概率,理想情况是0。
至于性能,可以参看这里,大概75%缓存命中是性能的分界线。
Memcache hit ratio: 100% (everything was in cache)
Query for entities: 3755 ms
Query/memcache/ndb: 3239 ms
Keys-only query: 834 ms
Memcache.get_multi: 2387 ms
ndb.get_mutli: 0 ms
Memcache hit ratio: 75%
Query for entities: 3847 ms
Query/memcache/ndb: 3928 ms
Keys-only query: 859 ms
Memcache.get_multi: 1564 ms
ndb.get_mutli: 1491 ms
Memcache hit ratio: 50%
Query for entities: 3507 ms
Query/memcache/ndb: 5170 ms
Keys-only query: 825 ms
Memcache.get_multi: 1061 ms
ndb.get_mutli: 3168 ms
Memcache hit ratio: 25%
Query for entities: 3799 ms
Query/memcache/ndb: 6335 ms
Keys-only query: 835 ms
Memcache.get_multi: 486 ms
ndb.get_mutli: 4875 ms
Memcache hit ratio: 0% (no memcache hits)
Query for entities: 3828 ms
Query/memcache/ndb: 8866 ms
Keys-only query: 836 ms
Memcache.get_multi: 13 ms
ndb.get_mutli: 8012 ms
尽可能的禁用索引。
为所有不需要的被query()和order()的字段,使用
indexed=False当你插入一条数据时,每个索引字段都会产生write Op,特别当操作对象是ListProperty,会根据list的数量,倍数消耗写配额。
对于一些查询,有些和实际逻辑需求相左,但能大幅节约Op的手段。。
class EntryCollect(ndb.Model): apublished = ndb.DateTimeProperty() need_collect_word = ndb.BooleanProperty(default=True, indexed=False) key_word = ndb.StringProperty(repeated=True, indexed=False)
对于原先是in(List)的查询:
keys = EntryCollect.query().order(-EntryCollect.published)
entrys = ndb.get_multi(keys.fetch(PER_PAGE*2, keys_only=True))
new_entry = []
for entry in entrys:
if keyword.decode('utf-8') in entry.key_word:
new_entry.append(entry)
对于原先是list.IN(other_list)的查询:
keys = EntryCollect.query().order(-EntryCollect.published)
entrys = ndb.get_multi(keys.fetch(PER_PAGE*2, keys_only=True))
top_entry = []
for entry in entrys:
if set(other_list).intersection(set(entry.key_word)):
top_entry.append(entry)
对于原先是Boolean的字段:
keys = EntryCollect.query().order(-EntryCollect.published)
entrys = ndb.get_multi(kesy.fetch(CONT*2, keys_only=True))
for entry in entrys:
if entry.need_collect_word:
# do something
projected()的利弊权衡
- 使用projected()的字段,必须被indexed。
- 使用projected()的查询,算一次small Op。
这里就有个权衡,如果read Op紧张,write Op富裕,那么就可以使用projected()。
绞尽脑汁使用Memcache
- Memcache是免费的! Memcache是免费的! 这个必须说两遍,Query太贵了。
- Query.get()会自动被缓存。
将查询的参数作为key,取md5,查询的结果用json存储起来。
json_data = memcache.get('{}:XXXXXXX'.format(md5sum)) if json_data is None: # do something.... json_data = json.dumps(data) memcache.add('{}:Analyse'.format(md5sum), json_data, MEMCACHE_TIMEOUT)
TextProperty 和 StringProperty的区别
- 在管理后台,你无法添加TextProperty的字段,StringProperty可以。
- TextProperty无法生成索引,StringProperty可以。
- StringProperty的最大长度是 1500 bytes。
拆分App
一个App拆分成多个App,是最简单的,倍翻利用app engine的方法。
应用间通信,使用什么格式最效率?
根据我自己的测试结果:
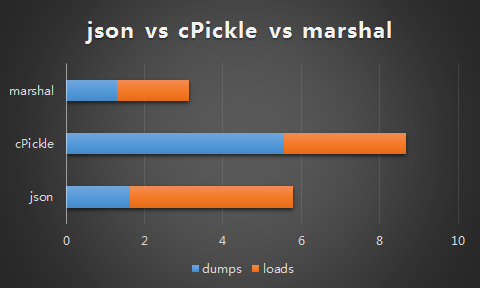
marshal取胜,而且处理utf-8更简便一些,但切记marshal不能用于两个不同版本的python之间序列化数据,不适用于开放的api。
如果使用json,要随时注意编码:
form_fields = {
"something": self.request.get("something", default_value="").encode("utf-8"),
}
form_data = urllib.urlencode(form_fields)
result = urlfetch.fetch(url=SOME_URL,
payload=form_data,
method=urlfetch.POST,
follow_redirects=False,
headers={'Content-Type': 'application/x-www-form-urlencoded'})
self.response.headers['Content-Type'] = 'application/json'
self.response.out.write(result.content)
节省各种配额
- 在一个Instance内,不管cpu占有率高低,cpu time都一样计费。
- 删除数据库也占用write Op,没用的资源尽早删除。
- 绞尽脑汁优化内存和cpu使用。
节省CPU配额:使用asynchronous urlfetch
为节约网络延迟而浪费的cputime,使用异步urlfetch就十分重要。 官方手册在这里,例如:在抓取多个feed时:
q = Feed.query()
results = ndb.get_multi(q.fetch(keys_only=True))
rpcs = []
for f in results:
rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(rpc, f.url)
rpcs.append(rpc)
for rpc in rpcs:
rpc.wait()
result = rpc.get_result()
d = feedparser.parse(result.content)
for e in d['entries']:
# do something....
节省CPU配额:需要初始化的资源,在本地进行序列化,GAE上直接读取序列化的资源。
以jieba词库为例:默认情况,jieba每次初始化,都会将本地词库dict.txt进行readline操作,生成字典,这个过程在GAE默认的CPU上需要将近6秒。先将这个字典在本地使用marshal.dump,在GAE中在load,初始化阶段则只消耗1.x秒。
try:
with open(cache_file, 'rb') as cf:
object_a, object_b = marshal.load(cf)
except :
for line in open(dict, 'rb').read().decode('utf-8').splitlines():
# do something....
with open(cache_file, 'wb') as cf:
marshal.dump((object_a, object_b), cf)
节省CPU配额:不使用memcache,如何缓存一个页面
能省则省,虽然memcache免费的,但还想省掉cpu怎么办?
self.response.headers['Cache-Control'] = 'public, max-age:300'
self.response.headers['Pragma'] = 'Public'
资源优化:删掉过时的数据
节约数据库存储空间最简单的方法,就是删掉过时的数据,而对于ndb,不存在Object.query().del() 这样的方法,需要使用:
earliest = datetime.datetime.now() - datetime.timedelta(days=10)
keys = EntryCollect.query(EntryCollect.published <= earliest).fetch(keys_only=True)
ndb.delete_multi(keys)
资源优化:使用robots.txt
减少搜索引擎对app的负载,不失为一个办法,一个个位数pv的app,被bot拖到配额超限真的好23333...
后记
然后?然后就没有然后了...
我用一个周末django写的app,用了2个周末迁移到gae上,跟配额,特别是Datastore write/read Op奋斗了2个星期,经验写出来,希望同样蛋痛的V友们少走弯路。
本人不是职业程序员,金融从业者,希望少拍代码砖=.=
 |
1
xieyingli 2015-06-21 11:00:41 +08:00
大神你研究过直接抓交易数据么?
|
 |
2
lbp0200 2015-06-21 11:08:19 +08:00 via Android
买个VPS没多少钱
|
 |
6
dantifer 2015-06-21 11:15:18 +08:00
用openshift吧,也是免费的,比GAE强多了,
|
 |
7
geeklian OP @dantifer 谢谢建议,说真的...没想比较太多,就想着随便找个跑起来,以后不怕折腾vps了。
|
 |
8
lemayi 2015-06-21 11:25:58 +08:00
v2ex应该多一点这样的帖子。
非常感谢楼主的分享。 另外为啥不弄个vps。 一个月也不是很贵啊。 GAE如果超额收钱的话,貌似也不便宜把。 |
|
9
geeklian OP @lemayi 原因里也说过了,本来就是跑在vps里的,但vps老想着折腾,自己管不住自己的手,所以就想到移到一个xAE里,选GAE完全是惯性思维...
|
 |
10
101 2015-06-21 11:38:01 +08:00
socket 这个 openshift 也不支持,PAAS 限制很多 ,不同的应用只能用它指定的端口,上次问搜狐云景 Web Service 开其他端口还要单独申请,由于限制,折腾起来比 VPS 还费神,各家部署方式还不同
|
 |
11
lilydjwg 2015-06-21 11:54:46 +08:00
所以,为啥你要用 GAE 呢?不考虑墙的话,免费的服务有不少啊。而且扔 VPS 上跑也更方便,比如 jieba 那货可以单独放一进程里,就只需要初始化一次、占用一份内存了。
|
 |
12
ulic95 2015-06-21 12:15:54 +08:00
好贴~
|
 |
13
0x17e 2015-06-21 12:27:28 +08:00
看这个架势,即便用上 VPS,也还是会有其他方面的折腾。
爱折腾的人总是停不下来,因为这个世界是不完美的。 |
 |
14
spance 2015-06-21 13:27:35 +08:00
你抱着接近企业级的理想和要求,却在尝试着free service,然后抱怨各种限制各种不够各种不爽,那么谁家的service可以free还能包爽包满意还可以不签合同?
GAE仅是一个paas而已,而且很明确的给出了limits表格,那还要他怎么做呢? 既然有要求,就要有追求,省得掏银子,GCE/storage/DB等的性能应该大概可以满足你。 还有,load balance和全球load balance人家也是有的。 |

 |
16
raincious 2015-06-21 13:57:53 +08:00
@spance
GAE定价比较贵,早先有人2000个访问收费¥1200的,可见费用多高。 =================== 大型程序不适合放在GAE上,只能放一些轻量级的。 > 每五分钟抓一些feed,然后jieba分词,然后推送消息...已经超免费配额了 这个你可以放在后端,用后端实例(比如B1等等、前端是F1等等),每天可以有9小时配额时间,不限制超时(当然,9小时之后就会被杀)。后端程序可以随时关闭和限制Instance数量(比如用basic_scaling)。前端还是老老实实做前端的事,只负责数据显示就好。 但是注意,要关闭后端实例的话,GAE会在实例关闭15分钟之后的才停止计费。就是说,如果你0:00关掉了实例,GAE会计费你用到了0:15,比如:  你可以看到实例已经关闭了(黄线),但是仍然在计费(绿线),直到15分钟之后消失。 所以这就不太合适每5分钟抓取一次了(45-50分钟抓取一次应该刚好,但这取决于你抓取需要的时间)。 |
 |
17
angkec 2015-06-21 14:38:50 +08:00
2011 12年左右的时候GAE突然涨价到这个水平. 好几个项目都要迁移. 从此发誓再碰GAE剁手.
于是入了Heroku这个坑, 不过坑浅多了. |
|
19
geeklian OP @spance
这个跟你想不想花钱没关系,除非是中国的国企,任何单位使用gae都会面临计费的问题。如何优化都是必须考虑的问题。 |
|
20
geeklian OP @raincious 你说的方法企业考虑过...
但我本来是为了推送股票咨询,这个对时效性的要求是5分钟。 事实上F2配额的方法也考虑过,后来也尝试过2个app分别服务14个小时,但天性爱折腾,后来确实靠将词库本地序列化后再上传,直接节省了4/5的cpu和1/2的内存。一个实例的免费配额也能应付了。 |
 |
21
yegle 2015-12-08 08:28:16 +08:00 来晚了…
有几个改进的方法: 1. warmup request ,配置一个 URL 用于 warmup ,接收到请求的时候把 jieba 的初始化做掉 2. 外部数据库的问题, GAE 只支持 Google Cloud SQL 这一种关系型数据库。非关系型数据库很多是提供 REST API 的,可以用 URLFetch 做。 Socket API 并不是用来连接数据库用的。 3. 部分耗时过长的请求可以用 backend 来处理,不受 1 分钟的限制 4. feed 获取可以用 task queue 定时缓存到 datastore 或 memcache 里 datastore 方面的优化你提的都有道理。 |
|
22
geeklian OP @yegle 谢谢....
最近在逐渐把一些 vps 停掉,把一些自用的简易 app 、 blog 、爬虫移到 gae 上。自用的一些小程序,在 gae 的免费配合足够的情况下,真是最好的选择了... |
|
23
yegle 2015-12-12 02:55:19 +08:00
@geeklian GAE 的费用也没那么贵
Google Cloud SQL 10G 存储 24/7 使用,一个月 13 刀左右 Google Cloud Datastore 10G 存储每秒 10 次读写,一个月 30 刀左右 https://cloud.google.com/products/calculator/#id=4588b602-5f0c-4f4c-9caf-1646c806a940 |