
使用 StatsD + InfluxDB + Grafana 搭建 Node.js 监控系统 (二)
1heart · 2017-05-26 17:05:11 +08:00 · 3069 次点击这是一个创建于 2880 天前的主题,其中的信息可能已经有所发展或是发生改变。
文章来源:https://zhuanlan.zhihu.com/p/26981364?group_id=850365065449328641
上一篇主要讲了 StatsD + InfluxDB + Grafana 的搭建并用 Grafana 创建了两种图表( Graph ):
api 每个接口的请求量 api 每个接口的响应时间 这一篇主要讲讲两个深入使用 Grafana 的方式:
1、如何将 Grafana 跟 ELK 紧密的结合起来
2、Grafana 监控报警
Grafana + ELK
在观察 Grafana 监控时,发现某个 api 接口响应时间突然有一个尖刺,这个时候的表情是:

不过别急,我之前写过一篇《Koa 请求日志打点工具》讲了如何打点 Koa 应用,将慢日志收集到 ELK,可以看到具体某个请求每一步 yield 表达式的执行耗时。那如何将 Grafana 和 ELK 中的打点日志结合起来呢?我们深入研究下 Grafana,会发现一个可用的功能:Grafana 的图表可以添加 link,如下:
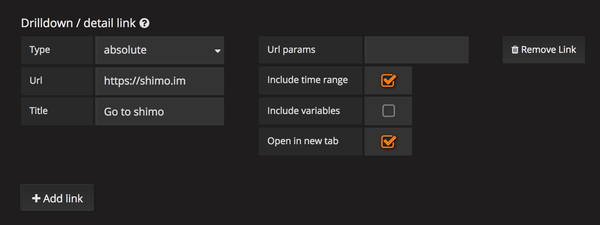
上图选项的意思是:当鼠标悬浮在图表的左上角时,会弹出一个名为 Go to shimo 的链接,点击会跳转到 https://shimo.im。记住勾选上 Include time range,这是关键所在。
Kibana-RequestId-Link
勾选 Include time range 会在 querystring 里添加 from=xxx&to=xxx,而且当选取范围时 Grafana 的 time range 格式跟 Kibana 的还不太一样。于是我写了一个 Chrome 插件 kibana-requestId-link,解决了两个问题:
1、转换 time range 格式。即从 Grafana 带到 Kibana 的 time range ( from 和 to )转化成 Kibana 认识的 time range,并重定向。
2、给 requestId 添加 link。点击后跳转到限定在相同时间范围内通过该 requestId 查询的结果,省了自己再粘贴复制到 Kibana 查询一遍的过程。 该插件已发布到 Chrome App Store,下载地址。
安装完插件后,我们还需要修改初始化 Grafana 响应时间图表的脚本,将:
links: []
改为:
"links": [
{
"title": "Go to kibana",
"type": "absolute",
"keepTime": true,
"targetBlank": true,
"url": "http://你的 kibana 地址 /app/kibana#/discover?_g=(refreshInterval:(display:Off,pause:!f,value:0),time:(from:now-1h,mode:quick,to:now))&_a=(columns:!(routerName,sumOfTake,requestId),index:'logstash-*',interval:auto,query:(query_string:(analyze_wildcard:!t,query:'app:%22api%22%20AND%20routerName:%22<%= action %>%22%20AND%20_exists_:%22sumOfTake%22')),sort:!('@timestamp',asc))"
}
]
这里有两点需要说明:
1、url 里默认 time:(from:now-1h,mode:quick,to:now),kibana-requestId-link 插件会将这个值替换掉。
2、query_string 里查询语句为:
app:"api" AND routerName:"xxx" AND _exists_:"sumOfTake"
这里是针对我们业务 api 的 lucene 查询语句。app 限定为 api 的日志,routerName 表明是哪个接口,_exists_:"sumOfTake" 表明是请求最后一步的 log (因为只有慢日志和错误日志的最后一步才加了 sumOfTake 字段)。一句话解释:查询某个时间段内,api 某个接口的所有慢请求和错误请求。 举个真实的例子,过去一小时 file.star 这个接口的响应时间图表:
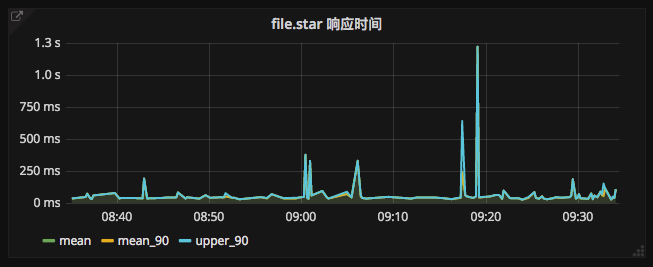
可以看出,在 09:17 和 09:19 左右分别有一个尖刺(响应时间大于 500ms ),点击 Go to kibana 跳转到 Kibana,如下:
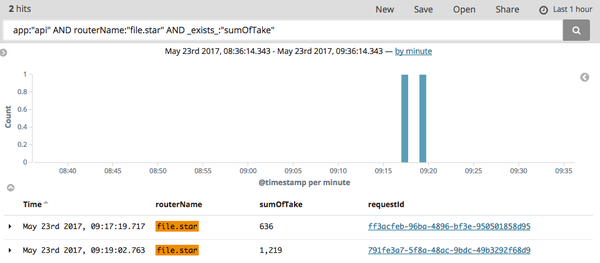
有两条慢日志,且时间点和响应时间都吻合(这里没有错误请求日志)。我们点击第二条慢日志的 requestId,跳转到如下:
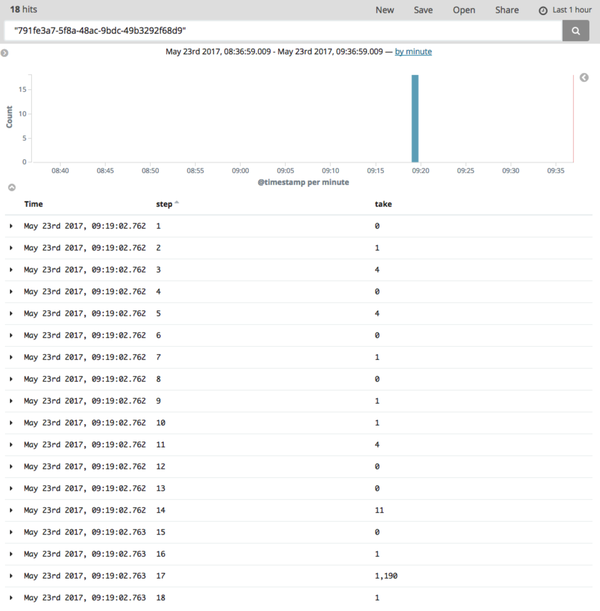
可以看出从请求到来到结束执行了 18 步,大部分 step 执行时间都很短,但在 step=17 这一步执行了 1190ms,点击左边展开查看具体信息:
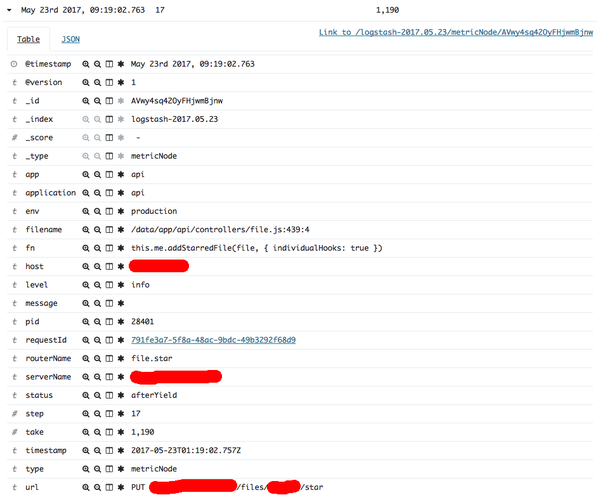
url 表明是哪个接口,fn 表明 yield 表达式是 this.me.addStarredFile(file, { individualHooks: true }),filename 表明代码在 /data/app/api/controllers/file.js:439:4,status 是 afterYield 表明这个 yield 表达式执行的时间( beforeYield 表示上个 yield 表达式执行之后到这个 yield 表达式执行之前),take 表明执行了 1190ms。
Grafana 监控报警
Grafana v4 版本加入了报警( Alert )功能。
首先,点击左上角图标弹出选项菜单->Alerting->Alert List->Configure notifications。如果没有 channel,点击 New Channel 创建一个。创建或修改 channel 都如下所示:
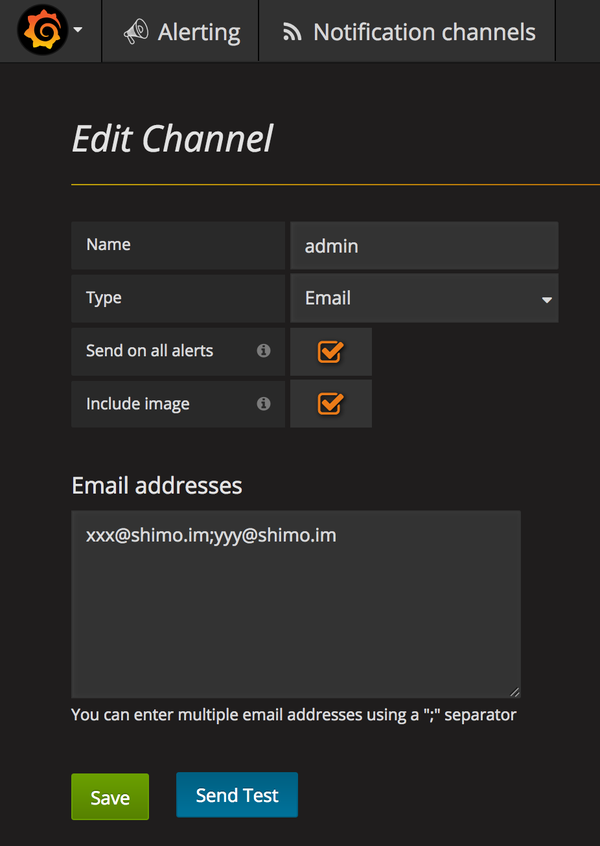
Email addresses 中 email 地址以分号隔开。点击 Send Test 测试是否能收到邮件。
注意:需要配置 Grafana 的使用邮箱地址。
回到具体的监控图表,进入编辑页面,有一个 Alert tab 页,如下:
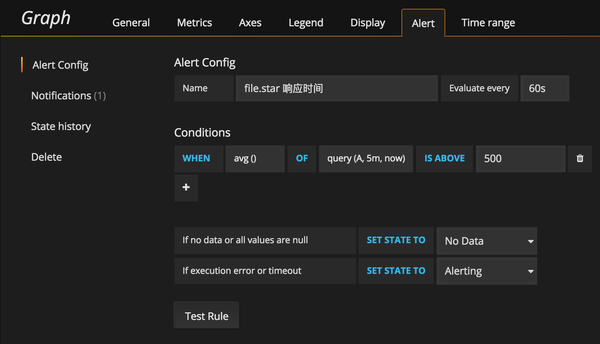
上图选项的意思是:给 file.star 接口加一个监控报警,每 60s 检查一次,如果过去 5m 平均响应时间大于 500ms 则发送报警邮件。Notifications 可以设置发送到哪些 channel,这里设置只发送到 admin 这个 channel,可以在 Message 里填写详细的描述,State history 保存了所有报警历史。
对应的我们需要修改创建响应时间图表的脚本,添加 alert 字段:
{
"alert": {
"conditions": [
{
"evaluator": {
"params": [
500
],
"type": "gt"
},
"operator": {
"type": "and"
},
"query": {
"params": [
"A",
"5m",
"now"
]
},
"reducer": {
"params": [],
"type": "avg"
},
"type": "query"
}
],
"executionErrorState": "alerting",
"frequency": "60s",
"handler": 1,
"name": "<%= action %> 响应时间",
"noDataState": "no_data",
"notifications": []
},
...
"id": <%= panelId %>
}
注意:这里的 A 即之前 mean 的 refId。 收到的报警邮件会带有当前监控图表的 screenshot,如下所示:
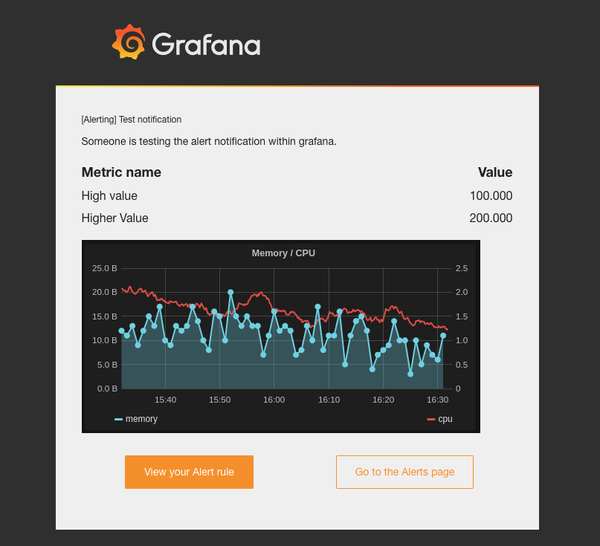
最后
我们正在招聘!
 |
1
yghack 2017-05-26 17:09:48 +08:00
图挂了
|
 |
2
rrfeng 2017-05-26 17:56:29 +08:00 via Android statsd 会有性能瓶颈...千万注意 CPU 使用率。特别是用 repeater 的时候。
influxdb 只能显示一万个 measurements |

 |
5
johnlui 2017-06-06 10:26:23 +08:00
图片来自知乎,挂了。。。
|