公司需求 所以开始写爬虫
第一次写 直接 curl 请求 web 端 折腾了一下午算是搞定了 可是速度很慢 而且频繁被验证码限制
第二天搞了台拨号的机器 每次验证码就直接断了宽带重新拨号(动态 ip ) 但是速度还是很慢
第三天刷了一下关于爬虫的乱七八糟的知识 开始重写
重写是利用 curl_multi 进行并发请求 这次是爬 H5 端 H5 端验证码的频率比 web 端要低很多
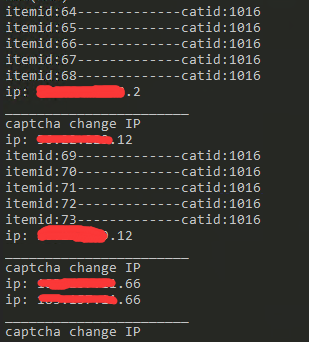
但是新的问题出现了 放到之前拨号的机器上基本上一个页面就弹一次验证码 换 IP 也一样
本地跑就不会这样 而且重拨后 curl_multi 就会报链接超时的错误 于是就放在本地跑
但是验证码的问题还是没有解决 于是就开始摸索网站验证码的规律
几天下来还是没有太大的发现 不管是降低访问频率 还是更改爬取顺序 基本上都没什么太大变化
于是考虑从过验证码下手 验证码是纯底色 没有干扰 只是字体会变形旋转
又折腾了下 Tesseract-OCR 识别率太低 达不到想要的效果
想问几个问题 :
- 电商网站一般都是什么反爬虫策略? 被验证码限制最多的时候就是一个循环完成后 下一个循环第一个页面被限制,最近几天在其他时候被验证码限制的情况发生频率高了一些 有用 sleep()限制频率依然没什么用
- 爬虫 dalao 们都是怎么对抗验证码的 除了代理 IP,以及对验证码识别有没有什么效率比较高的办法 看 Tesseract-OCR 是有深度学习?的特性 但是没搞太明白
- 拨号的那台机器用爬 H5 端的爬虫为什么会这么频繁被限制本地却不会这样 每次重拨大概率 IP 都会换 应该不是黑名单的问题吧?本地基本都是输入验证码接着重新开一下爬虫就好了
- 如果用 php-thread 真正独立线程编写爬虫 重拨 IP 会不会出现超时的 error
- Tesseract-OCR 配置 tessedit_char_whitelist 后会报错 read_params_file: Can't open tessedit_char_whitelist; 白名单只是添加了 a-z
作为新手可能会问出比较蠢的问题 水平有限 希望见谅 = =
有需要提供更多详细信息的我会补充 爬虫工具是用的 V2dalao querylist 致谢