
这是一个创建于 2325 天前的主题,其中的信息可能已经有所发展或是发生改变。
前言
为了解决 LVS ksoftirqd CPU 使用率 100%导致网卡软中断丢包,我和同事们一起搜索了大量的资料去分析问题,特别是感谢美团技术团队的分享帮助我们快速梳理优化思路,最后明确了如何重构 RPS 和 RFS 网卡多队列的优化脚本。个人认为这是一个大家可能普遍会遇到的问题,文章内的分析思路和解决方案未必是最优解,也欢迎各位分享自己的解决方法。
RPS 和 RFS 网卡多队列性能调优实践
更新历史
2019 年 07 月 03 日 - 初稿
阅读原文 - https://wsgzao.github.io/post/rps/
扩展阅读
Redis 高负载下的中断优化 - https://tech.meituan.com/2018/03/16/redis-high-concurrency-optimization.html
事故复盘
我们遇到的问题属于计划外的 incident,现象是某产品用户在线率突然降低,LVS Master 同时收到 CPU High Load 告警,检查发现该节点出现网卡大量断开重连和丢包情况,应急切换到 LVS Slave 也出现上述问题,在排除掉流量异常和外部攻击后选择切换 DNS 到背后的 Nginx Real Servers 后服务逐步恢复。
复盘核心原因在于系统初始化时 rps 优化脚本没有成功执行,这个脚本起初是因为早期 DBA 团队遇到过 CPU 负载较高导致网卡异常,这个优化脚本也一直传承至今,却已经没有人知道为什么添加。现在大多数服务器没有执行成功而被大家一直所忽视显然也是 post check 没有做到位。在早期大家都停留在 Bash Shell 运维的阶段,没有专职的团队来管理确实容易失控,好在现在可以基于 Ansible 来做初始化和检查,运维的压力也减轻了一部分。
通过 Google 搜索相关知识的过程中,我们也发现在不少人都会遇到这样类似的问题。比如这篇文章提到lvs/irq
- 瓶颈现象:当压力较大时,Lvs 服务器 CPU 的其中一个核使用率达到 100%(处理软中断)。
- 当 Lvs 服务器处理软中断的那个核使用率达到 100%,就到达系统处理上限。
- 占用 CPU 的是进程 “ ksoftirqd ”,它未能使用到多核。
- 做双网卡绑定,然后调试内核 SMP,中断主要是来自网卡的,不是 LVS 本身。需要把 2 个网卡来的 IRQ 均衡在双核 CPU 上面。
和华为的工程师们在交换经验的时候对方分享了一个关于 RSS 和 RPS 关系图,之后的内容还会引用美团技术团队的分析
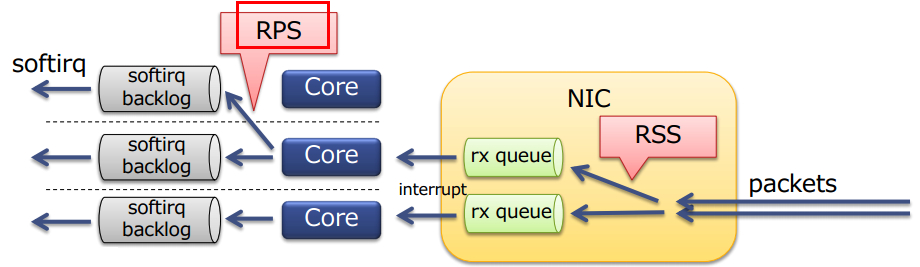
我们遇到的情况是缺少可用服务器资源选择把用户外部请求流量和 Codis Cache Cluster 内部流量临时混在了同一个 LVS 上,虽然看上去 CPU 和 traffic 的整体压力都不算高,但是 CPU 的处理压力可能恰好集中在了和外网 Bond1 网卡相同的 Core 上最后引起了 ksoftirqd 软中断,而内网 Bond0 网卡就没有监控到任何丢包。虽然我们也有正常开启irqbalance,但不清楚是不是因为受到cpupower performance和NUMA的影响最后也没能阻止事故的发生,最终的优化方案主要是手动开启 RPS 和 RFS,大致步骤如下:
- set cpupower
cpupower frequency-set -g performance,CPU 优化建议使用 cpupower 设置 CPU Performance 模式 - activate rps/rfs by script: rps.sh
- double ring buffer size:
ethtool -G p1p1 [rx|tx] 4096, checkethtool -g p1p1 - double NAPI poll budget:
sysctl -w net.core.netdev_budget=600 - add zabbix monitor on net.if.in[eth0,errors,dropped,overruns]
#!/bin/bash
# chkconfig: 2345 90 60
### BEGIN INIT INFO
# Provides: rps
# Required-Start: $local_fs $remote_fs $network $syslog
# Required-Stop: $local_fs $remote_fs $network $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: enable rps config for ubuntu
# Description: enabele rps which is a kernel tweak for network performance
### END INIT INFO
NAME=rps
DESC=rps
# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
# cpupower frequency-set -g performance
# activate rps/rfs by script: https://gist.github.com/wsgzao/18828f69147635f3e38a14690a633daf
# double ring buffer size: ethtool -G p1p1 [rx|tx] 4096, ethtool -g p1p1
# double NAPI poll budget: sysctl -w net.core.netdev_budget=600
rps() {
net_interface=`ip link show | grep "state UP" | awk '{print $2}' | egrep -v '^docker|^veth' | tr ":\n" " "`
for em in ${net_interface[@]}
do
rq_count=`ls /sys/class/net/$em/queues/rx-* -d | wc -l`
rps_flow_cnt_value=`expr 32768 / $rq_count`
for ((i=0; i< $rq_count; i++))
do
echo $rps_flow_cnt_value > /sys/class/net/$em/queues/rx-$i/rps_flow_cnt
done
flag=0
while [ -f /sys/class/net/$em/queues/rx-$flag/rps_cpus ]
do
echo `cat /sys/class/net/$em/queues/rx-$flag/rps_cpus | sed 's/0/f/g' ` > /sys/class/net/$em/queues/rx-$flag/rps_cpus
flag=$(($flag+1))
done
done
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries
sysctl -p
}
check_rps() {
ni_list=`ip link show | grep "state UP" | awk '{print $2}' | egrep -v "^docker|^veth" | tr ":\n" " "`
for n in $ni_list
do
rx_queues=`ls /sys/class/net/$n/queues/ | grep "rx-[0-9]"`
for q in $rx_queues
do
rps_cpus=`cat /sys/class/net/$n/queues/$q/rps_cpus`
rps_flow_cnt=`cat /sys/class/net/$n/queues/$q/rps_flow_cnt`
echo "[$n]" $q "--> rps_cpus =" $rps_cpus ", rps_flow_cnt =" $rps_flow_cnt
done
done
rps_sock_flow_entries=`cat /proc/sys/net/core/rps_sock_flow_entries`
echo "rps_sock_flow_entries =" $rps_sock_flow_entries
}
case "$1" in
start)
echo -n "Starting $DESC: "
rps
check_rps
;;
stop)
echo -n "Stop is not supported. "
;;
restart|reload|force-reload)
echo -n "Restart is not supported. "
;;
status)
check_rps
;;
*)
echo "Usage: $0 [start|status]"
;;
esac
exit 0
Scaling in the Linux Networking Stack
了解 RSS、RPS、RFS 等基础知识很重要
This document describes a set of complementary techniques in the Linux networking stack to increase parallelism and improve performance for multi-processor systems.
The following technologies are described:
- RSS: Receive Side Scaling
- RPS: Receive Packet Steering
- RFS: Receive Flow Steering
- Accelerated Receive Flow Steering
- XPS: Transmit Packet Steering
https://www.kernel.org/doc/Documentation/networking/scaling.txt
RPS
Receive Packet Steering (RPS) is similar to RSS in that it is used to direct packets to specific CPUs for processing. However, RPS is implemented at the software level, and helps to prevent the hardware queue of a single network interface card from becoming a bottleneck in network traffic.
RPS has several advantages over hardware-based RSS:
-
RPS can be used with any network interface card.
-
It is easy to add software filters to RPS to deal with new protocols.
-
RPS does not increase the hardware interrupt rate of the network device. However, it does introduce inter-processor interrupts.
RPS is configured per network device and receive queue, in the /sys/class/net/*device*/queues/*rx-queue*/rps_cpus file, where device is the name of the network device (such as eth0) and rx-queue is the name of the appropriate receive queue (such as rx-0).
The default value of the rps_cpus file is zero. This disables RPS, so the CPU that handles the network interrupt also processes the packet.
To enable RPS, configure the appropriate rps_cpus file with the CPUs that should process packets from the specified network device and receive queue.
The rps_cpus files use comma-delimited CPU bitmaps. Therefore, to allow a CPU to handle interrupts for the receive queue on an interface, set the value of their positions in the bitmap to 1. For example, to handle interrupts with CPUs 0, 1, 2, and 3, set the value of rps_cpus to 00001111 (1+2+4+8), or f (the hexadecimal value for 15).
For network devices with single transmit queues, best performance can be achieved by configuring RPS to use CPUs in the same memory domain. On non-NUMA systems, this means that all available CPUs can be used. If the network interrupt rate is extremely high, excluding the CPU that handles network interrupts may also improve performance.
For network devices with multiple queues, there is typically no benefit to configuring both RPS and RSS, as RSS is configured to map a CPU to each receive queue by default. However, RPS may still be beneficial if there are fewer hardware queues than CPUs, and RPS is configured to use CPUs in the same memory domain.
RFS
Receive Flow Steering (RFS) extends RPS behavior to increase the CPU cache hit rate and thereby reduce network latency. Where RPS forwards packets based solely on queue length, RFS uses the RPS backend to calculate the most appropriate CPU, then forwards packets based on the location of the application consuming the packet. This increases CPU cache efficiency.
RFS is disabled by default. To enable RFS, you must edit two files:
/proc/sys/net/core/rps_sock_flow_entries
Set the value of this file to the maximum expected number of concurrently active connections. We recommend a value of 32768 for moderate server loads. All values entered are rounded up to the nearest power of 2 in practice.
/sys/class/net/*device*/queues/*rx-queue*/rps_flow_cnt
Replace device with the name of the network device you wish to configure (for example, eth0), and rx-queue with the receive queue you wish to configure (for example, rx-0).
Set the value of this file to the value of rps_sock_flow_entries divided by N, where N is the number of receive queues on a device. For example, if rps_flow_entries is set to 32768 and there are 16 configured receive queues, rps_flow_cnt should be set to 2048. For single-queue devices, the value of rps_flow_cnt is the same as the value of rps_sock_flow_entries.
Data received from a single sender is not sent to more than one CPU. If the amount of data received from a single sender is greater than a single CPU can handle, configure a larger frame size to reduce the number of interrupts and therefore the amount of processing work for the CPU. Alternatively, consider NIC offload options or faster CPUs.
Consider using numactl or taskset in conjunction with RFS to pin applications to specific cores, sockets, or NUMA nodes. This can help prevent packets from being processed out of order.
了解接收数据包的流程
这里摘取了美团技术团队的分析,在此表示感谢
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过 TCP/IP 协议逐层处理。
- 应用程序通过
read()从socket buffer读取数据。
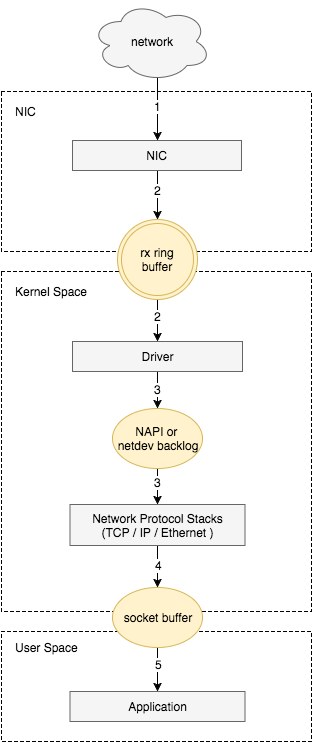
将网卡收到的数据包转移到主机内存( NIC 与驱动交互)
NIC 在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是 rx ring buffer。它是由 NIC 和驱动程序共享的一片区域,事实上,rx ring buffer 存储的并不是实际的 packet 数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做
sk_buffer; - 将上述缓冲区的地址和大小(即接收描述符),加入到
rx ring buffer。描述符中的缓冲区地址是 DMA 使用的物理地址; - 驱动通知网卡有一个新的描述符;
- 网卡从
rx ring buffer中取出描述符,从而获知缓冲区的地址和大小; - 网卡收到新的数据包;
- 网卡将新数据包通过 DMA 直接写到
sk_buffer中。
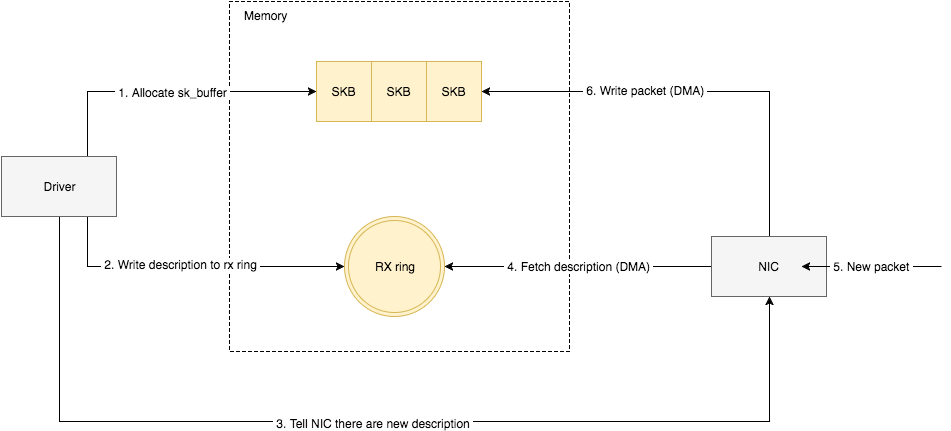
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC 接收到的数据包无法及时写到 sk_buffer,就会产生堆积,当 NIC 内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为 rx_fifo_errors,在 /proc/net/dev 中体现为 fifo 字段增长,在 ifconfig 中体现为 overruns 指标增长。
通知系统内核处理(驱动与 Linux 内核交互)
这个时候,数据包已经被转移到了 sk_buffer 中。前文提到,这是驱动程序在内存中分配的一片缓冲区,并且是通过 DMA 写入的,这种方式不依赖 CPU 直接将数据写到了内存中,意味着对内核来说,其实并不知道已经有新数据到了内存中。那么如何让内核知道有新数据进来了呢?答案就是中断,通过中断告诉内核有新数据进来了,并需要进行后续处理。
提到中断,就涉及到硬中断和软中断,首先需要简单了解一下它们的区别:
- 硬中断: 由硬件自己生成,具有随机性,硬中断被 CPU 接收后,触发执行中断处理程序。中断处理程序只会处理关键性的、短时间内可以处理完的工作,剩余耗时较长工作,会放到中断之后,由软中断来完成。硬中断也被称为上半部分。
- 软中断: 由硬中断对应的中断处理程序生成,往往是预先在代码里实现好的,不具有随机性。(除此之外,也有应用程序触发的软中断,与本文讨论的网卡收包无关。)也被称为下半部分。
当 NIC 把数据包通过 DMA 复制到内核缓冲区 sk_buffer 后,NIC 立即发起一个硬件中断。CPU 接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费 sk_buffer 中的数据,交给内核协议栈处理。
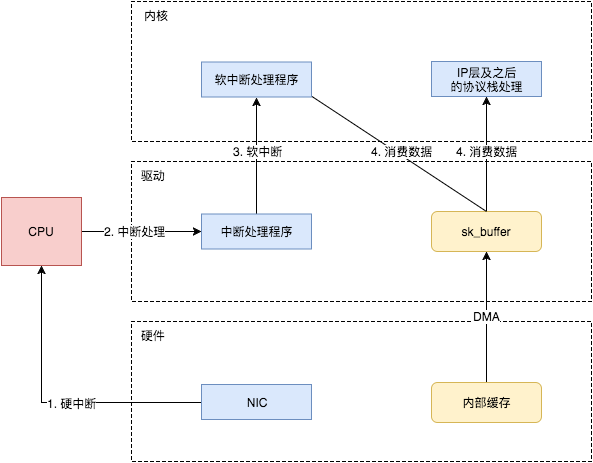
通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU 大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫 NAPI ( new API )的方式进行数据处理,其原理可以简单理解为 中断 + 轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
什么是中断?
由于接收来自外围硬件 (相对于 CPU 和内存) 的异步信号或者来自软件的同步信号,而进行相应的硬件、软件处理;发出这样的信号称为进行中断请求 (interrupt request, IRQ)
硬中断与软中断?
- 硬中断:外围硬件发给 CPU 或者内存的异步信号就称之为硬中断
- 软中断:由软件系统本身发给操作系统内核的中断信号,称之为软中断。通常是由硬中断处理程序或进程调度程序对操作系统内核的中断,也就是我们常说的系统调用 (System Call)
硬中断与软中断之区别与联系?
- 硬中断是有外设硬件发出的,需要有中断控制器之参与。其过程是外设侦测到变化,告知中断控制器,中断控制器通过 CPU 或内存的中断脚通知 CPU,然后硬件进行程序计数器及堆栈寄存器之现场保存工作(引发上下文切换),并根据中断向量调用硬中断处理程序进行中断处理
- 软中断则通常是由硬中断处理程序或者进程调度程序等软件程序发出的中断信号,无需中断控制器之参与,直接以一个 CPU 指令之形式指示 CPU 进行程序计数器及堆栈寄存器之现场保存工作 (亦会引发上下文切换),并调用相应的软中断处理程序进行中断处理 (即我们通常所言之系统调用)
- 硬中断直接以硬件的方式引发,处理速度快。软中断以软件指令之方式适合于对响应速度要求不是特别严格的场景
- 硬中断通过设置 CPU 的屏蔽位可进行屏蔽,软中断则由于是指令之方式给出,不能屏蔽
- 硬中断发生后,通常会在硬中断处理程序中调用一个软中断来进行后续工作的处理
- 硬中断和软中断均会引起上下文切换 (进程 / 线程之切换),进程切换的过程是差不多的
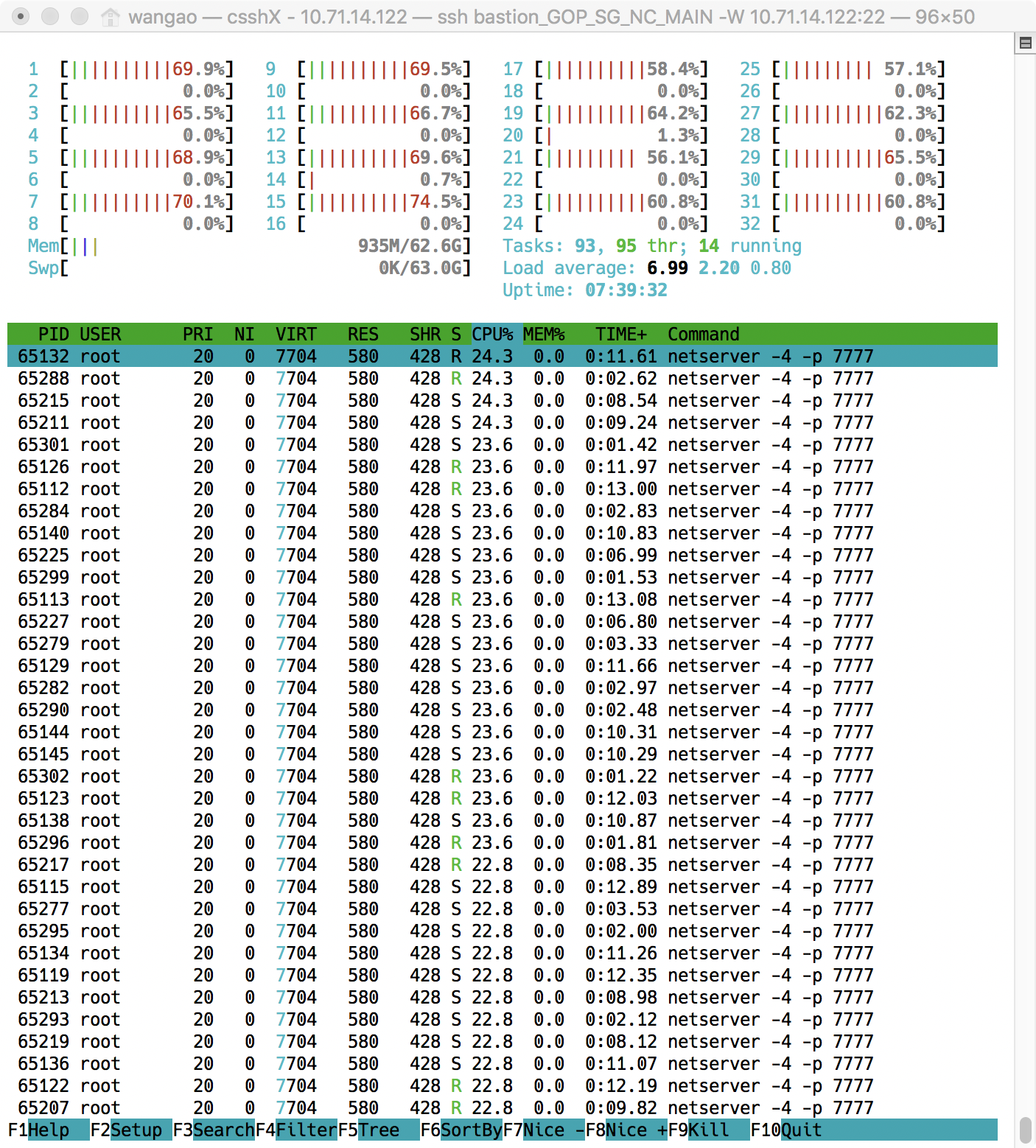
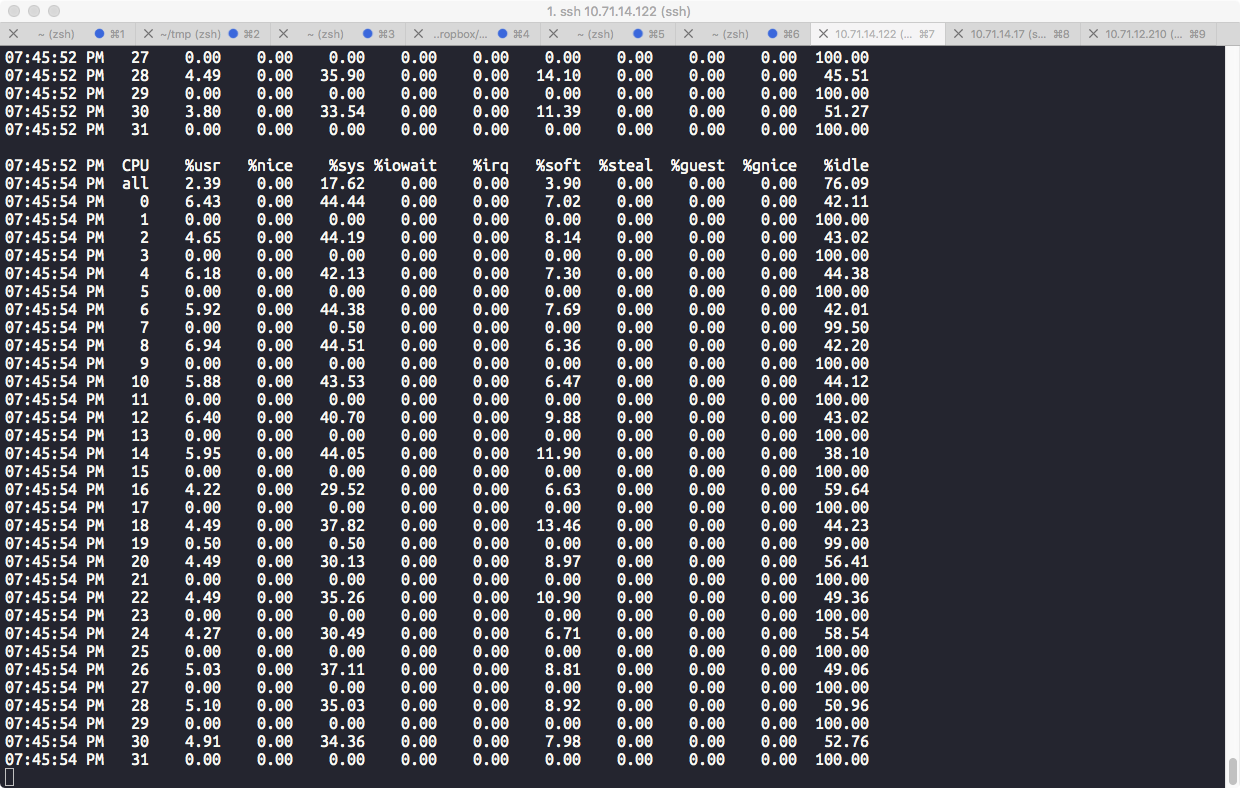
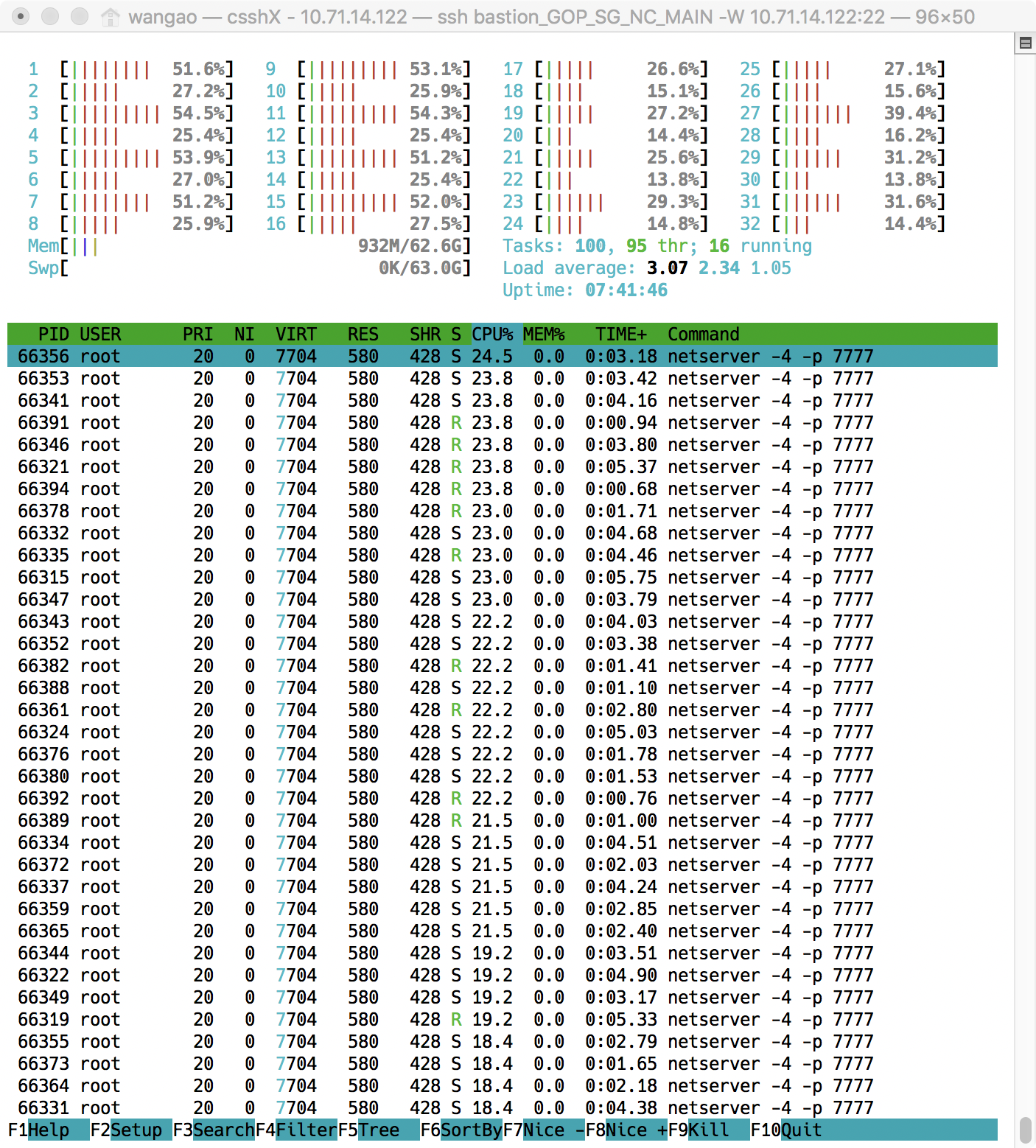
查看中断情况
1.top 按下数字键 1
- hi : time spent servicing hardware interrupts
- si : time spent servicing software interrupts
2.mpstat -P ALL 2
- irq 为硬中断
- soft 为软中断
mpstat 使用介绍和输出参数详解 - https://wsgzao.github.io/post/mpstat/
参考文章
Redis 高负载下的中断优化 网卡软中断过高问题优化总结 Linux 网络协议栈收消息过程 - TCP Protocol Layer Monitoring and Tuning the Linux Networking Stack: Receiving Data Performance Tuning Guide
 |
1
tt67wq 2019-07-05 17:19:55 +08:00
好文
|
 |
2
fakevam 2019-07-06 03:45:05 +08:00 RPS RFS 这一堆得东西,内核都是 hash...未必有收益
内核默认不开是有道理的 至于 si 打满,rps 和 rfs 基本对 si 没啥影响,更多是影响 sys 如果你的问题是 si 打满的话,irq balance 干掉,直接多网卡队列分散绑核就是了... 如果遇上多网卡队列还是不均衡,去调网卡的 hash 算法,看看 ethtool 显示你的网卡支持多少不同的 hash 算法 |
 |
3
wsgzao OP @fakevam #2 感谢分享,因为事故发生时没有办法仔细分析,事后分析的时候我们判断可能 NIC 第一层 ring buffer size 回环部分就被 drop 了,RPS 和 RFS 是在之后检查 init 步骤的是否发现有漏洞未执行,所以就顺手补上了
|
 |
4
xiaojinmaolove 2019-07-06 17:51:59 +08:00
好详细的复盘报告,支持干货楼主!
|