推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2339 天前的主题,其中的信息可能已经有所发展或是发生改变。
刚开始学习爬虫,上次有大佬在 V2 发了表情包的网站,今天想爬点表情包玩,发现加载页面是滚动加载的,看了下 network 加载的内容,
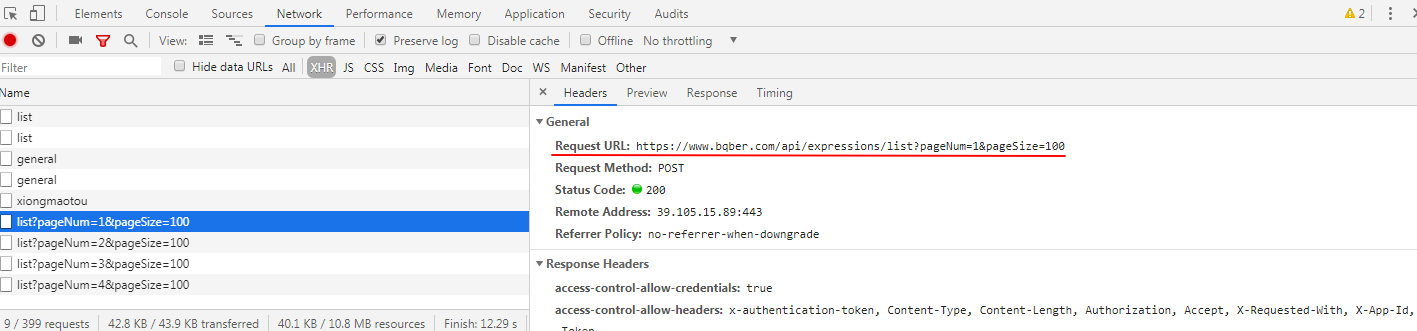 Request URL 这里的内容复制放到新页面地址栏无法加载,找不到思路了 ,求大佬解答!
之前爬别的滚动加载的页面,可以通过 Request URL 里的地址在新的页面打开,这种第一次遇见。
而且这个地址的内容和原本的页面地址也找不到关联的地方。
Request URL 这里的内容复制放到新页面地址栏无法加载,找不到思路了 ,求大佬解答!
之前爬别的滚动加载的页面,可以通过 Request URL 里的地址在新的页面打开,这种第一次遇见。
而且这个地址的内容和原本的页面地址也找不到关联的地方。
 |
1
different 2019-07-10 15:26:41 +08:00
一方面看是不是 POST 请求(看你的截图就是 post )
另一方面看看请求头(服务端可能检测来源等等) 所以直接复制到新页面地址栏当然无法加载。 |
 |
2
Karpov 2019-07-10 15:42:27 +08:00
可以考虑 puppeteer 这种实现
https://juejin.im/post/5ba1e99e6fb9a05d2b6db2eb |
 |
3
yamedie 2019-07-10 15:54:55 +08:00
@Karpov 这种小站感觉根本不需要动用 puppeteer..
node.js + super agent 扒列表, 随便找一个下载文件的包(比如 download), 就能完成这种任务 |
 |
4
snake8090 OP |
 |
5
Imlry 2019-07-10 16:01:41 +08:00
随手帮你写了。。。
https://imgur.com/a/P57H3Qi |
 |
6
Eric5845191 2019-07-10 17:21:36 +08:00
这个接口只支持 post 请求,直接放在地址栏是 get 请求,所以报错
|
|
7
snake8090 OP |
|
8
Karpov 2019-07-10 19:44:21 +08:00
试了一下,这个请求还对 body 有要求:
POST /api/expressions/list?pageNum=1& pageSize=100000 HTTP/1.1 Host: www.bqber.com Content-Type: application/json User-Agent: PostmanRuntime/7.15.2 Accept: */* Cache-Control: no-cache Postman-Token: 5ab5da52-bf5d-4d78-937b-80f914c0f34d,e7915629-e679-4617-912d-729dc02dc82e Host: www.bqber.com Accept-Encoding: gzip, deflate Content-Length: 13 Connection: keep-alive cache-control: no-cache {"name":null} 这样发过去就行了 |
 |
9
zgl263885 2019-07-10 19:56:27 +08:00 via iPhone
自动翻页只是前端用户界面的一种实现方式,根本的还是得看做了哪些网络请求
|
 |
10
trustbutverify 2019-07-10 19:57:10 +08:00 via iPhone
试试 pychrome
|
 |
11
whoami9894 2019-07-10 19:57:34 +08:00 via Android
楼上都好有耐心。。。
|
 |
12
ClericPy 2019-07-10 20:10:21 +08:00
对 python 来说,复制 curl bash,然后随便找个或者自己写个 curl Parser 发给 requests 就够了
|
|
13
ClericPy 2019-07-10 20:10:50 +08:00
写爬虫不管是靠它吃饭还是随便玩玩,http 那本书还是稍微读一下的好
|