
这是一个创建于 1111 天前的主题,其中的信息可能已经有所发展或是发生改变。
兄弟萌!我这个排序方法可以行得通吗?
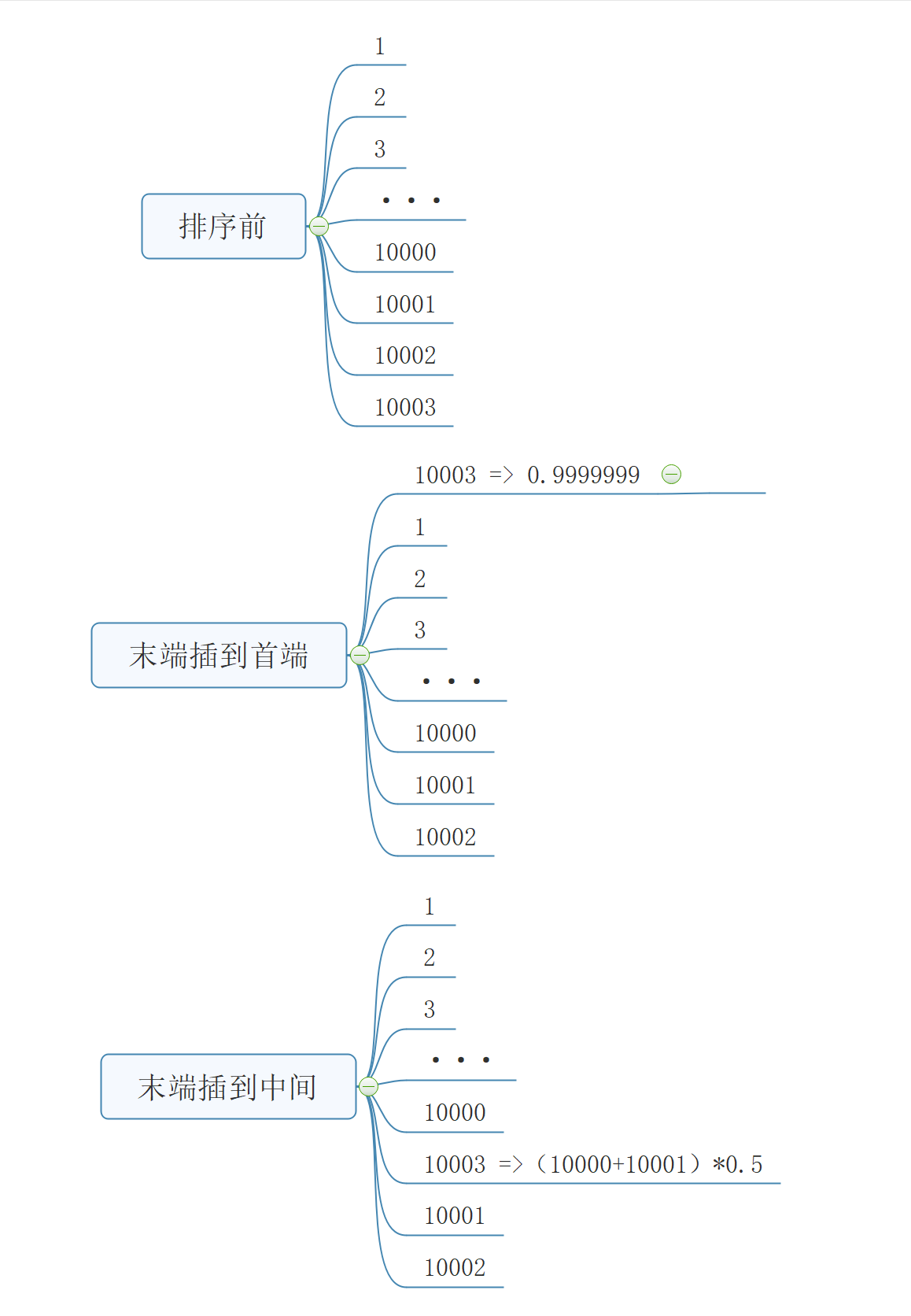
最近接到一个需求,技术栈 go+mysql 要给做个列表排序,一开始觉得很简单,直接加个排序号字段就 ORDER BY 好了 但是做一半我才发现,如果 100W 条数据 如果最后一条记录要排到第一位 排序号岂不是要整体记录都更新一次。
于是想了这个方案。 如图
 |
1
hejw19970413 2022-03-18 16:44:30 +08:00 没明白你要干什么
|
 |
2
userKamtao OP @hejw19970413 有没有看到图 我刚刚图格式没调对,就是 mysql 列表排序
|
 |
3
theoda 2022-03-18 16:47:06 +08:00
@hejw19970413 他的意思是在 1 前面直接插入 0.9 ,在 10001 前面插入 10000.5 ,就省得排序了
|
|
4
userKamtao OP @theoda 正解,这样就不用全部都更新一次了
|
 |
5
DarkFaith 2022-03-18 16:49:38 +08:00 记录分值,而不是记录序号,这样不需要排序。
另外 mysql 太慢,考虑 redis zset. |
|
6
theoda 2022-03-18 16:59:51 +08:00
同意 DarkFaith 。不过百万数据量 mysql 通常还是够用的。
|
 |
7
cpstar 2022-03-18 17:22:14 +08:00
这不就是吧 int 型的 id 变成了 float 型的 id 了么
|
 |
8
MoYi123 2022-03-18 18:00:52 +08:00
float 有精度上限, 用着用着就会失效了.
|
 |
9
cheng6563 2022-03-18 18:11:11 +08:00
精度有上限,用着用着还是得重排。。
|
 |
10
haharich 2022-03-18 18:57:42 +08:00
业务会有 100w 这种大量数据的排序列表场景吗,且某个数据还可以任意排
|
|
11
haharich 2022-03-18 19:04:44 +08:00
用时间戳当作分值,代替序列号,默认时间戳降序查,最后一条排到最前就更新为当前时间戳即可,排到中间就获取后面一条的时间戳+1 之类的?
|
 |
12
wd 2022-03-18 19:08:18 +08:00 via iPhone @DarkFaith 他那个序号也可以理解为分值了。我感觉这需求好奇怪,这么大数据量非要指定顺序.. 不知道真实需求是啥,比较怀疑是 x-y problem 。
|
 |
13
Inn0Vat10n 2022-03-18 19:08:42 +08:00
我们这有个线上系统就是这么做的,但就像上面说的精度是个问题,一段时间后可能需要重新刷序号
|
|
14
wd 2022-03-18 19:09:10 +08:00 via iPhone
如果你只是有有限的特殊数据,你也可以单独弄一个小表来记录这些特殊数据...
|
 |
15
lujjjh 2022-03-18 19:09:49 +08:00
不知道是不是类似 teambition 拖动排序的业务场景: https://www.zhihu.com/question/55789722/answer/146650607
这种场景每个分组里要排序的项目不会特别多,如果你要排序的数据量级真有 100w ,那估计这套方案也没法满足。 |
 |
16
oneisall8955 2022-03-18 19:15:01 +08:00 via Android
初始只有三个,A1 ,B2 ,C3
第一次:C 查到 AB 中间,于是 A1 ,C1.5 ,B2 第二次:B 插入 AC 中间,于是 A1 ,B1.25 ,C1.5 第三次:与此类推,A1 ,C1.125 ,B1.25 。。。。。 于是,N 次以后,BC 无限接近 1 ? |
 |
17
kzzhr 2022-03-18 19:56:13 +08:00
简单来说
有两个 index L 和 R ,现在有个 K 要插入到这俩中间,只需要 K=random(L,R) 就可以了 数值可以用 bigint ,基本不会出现相撞,出现的时候重排一下就行了 当然,最靠谱的还是单独存。。 |
 |
18
zmxnv123 2022-03-18 20:04:20 +08:00
这种更新方式简直就是为双向链表专门设计的,对应到 MySQL 中就是存前后 item 的 id ,此时更新的时间复杂度是 O(1) 的。可惜在 MySQL 中没法范围查询。
读取的场景可以用楼主的方法把主键缓存到 redis ,排序的时候先查 redis ,然后反查 MySQL 。我理解这个值只是一个虚拟值,没有实际含义,所以丢失了也没啥问题,毕竟 MySQL 中有原始数据,等精度不够了,用 MySQL 的数据重新刷 Redis 。 |
 |
19
xylophone21 2022-03-18 20:15:02 +08:00
每次插入的输入是什么?
比如现在是 A ,B,C ,C 差到 AB 中间。似乎输入只能是(A,C)? 那么数据结构里最适合插入的就是链表,每行存一个 next 字段,每次插入只需要插一次改一次。 链表最大的缺陷是找到要插入的这个点很慢,但通过索引数据库帮你解决了这个问题,所以应该不需要更复杂的数据结构了。 |
|
20
xylophone21 2022-03-18 20:20:53 +08:00
比如现在是 A ,B,C ,C 差到 AB 中间。似乎输入只能是(A,C)?
--》 比如现在是 A ,B,C ,D 差到 AB 中间。似乎输入只能是(A,D)? 当然,这个方案只能快速插入,不能输出序号,但你提的浮点数的方案也不能输出序号。这个需求目前不太明确。 |
 |
21
aphorism 2022-03-18 22:06:57 +08:00
如果应用场景就是会有大量不可预测位置的插入,而且需要保持序列,解决方案就是在排序字段上不要使用 Numeric order 而使用 lexical order ,但这样也需要该排序字段允许足够的长度来容纳大量的数据插入。使用浮点型作为排序字段是并不可靠的。
|
 |
22
documentzhangx66 2022-03-19 00:01:04 +08:00
对于静态数组:
22 、23 、24 、25 、26 、-1 、-1 value 大概率是保存在连续的内存空间。此时插入一个 21 并保持排序,那么这 5 个 value 在内存里的位置,就需要整体后移。 但有一种东西,叫链表,他们在内存里,大概率是这种样子: HeadNodeID:3 。 NodeID:1 ,Value:25 ,NextNodeID: 5 NodeID:2 ,Value:24 ,NextNodeID: 1 NodeID:3 ,Value:22 ,NextNodeID: 4 NodeID:4 ,Value:23 ,NextNodeID: 2 NodeID:5 ,Value:26 ,NextNodeID: -1 看着比较复杂,如果按 Value 排序,上图就变为: HeadNodeID:3 。 NodeID:3 ,Value:22 ,NextNodeID: 4 NodeID:4 ,Value:23 ,NextNodeID: 2 NodeID:2 ,Value:24 ,NextNodeID: 1 NodeID:1 ,Value:25 ,NextNodeID: 5 NodeID:5 ,Value:26 ,NextNodeID: -1 此时,插入 21 ,并且保持排序,就只需要: 增加一个 Node: NodeID:6 ,Value:21 ,NextNodeID: 3 然后把 HeadNodeID ,从 3 改为 6 就行。 数据库内的表的数据结构,大部分是基于 链表与静态数组 的高级复合型数据结构,并不是单纯的静态数组,所以你不需要过分担心这个问题,只需要设计好表结构与索引,然后正常使用就好,数据库不会傻到你加个值,重排序就把所有数据往后移。真实情况是,就像前面的例子,数据库只是加了个链表节点,然后修改了一下其他少数几个链表的指针,以及头结点,以及相关索引等。 |
 |
23
jones2000 2022-03-19 00:36:37 +08:00
1. 目前的数据量使用 mysql 是否可以满足需求。
2. 目前程序瓶颈在哪里,是否可以通过升级数据库配置来解决。 能用硬件解决的问题, 就花钱解决, 买硬件比花钱找人优化软件靠谱。 没必要不要自己写排序。 |
 |
24
yolee599 2022-03-19 01:02:07 +08:00 via Android
骚操作:用数据库实现双向链表
|
|
25
yolee599 2022-03-19 01:03:14 +08:00 via Android
如果需要快速定位再加一个跳表作为索引
|
 |
26
GeruzoniAnsasu 2022-03-19 02:48:25 +08:00
@xylophone21
@zmxnv123 @documentzhangx66 链表存的话读取会非常慢,不能范围预加载,OFFSET 更是灾难,因为现在没有记录告诉你 第二页第一行对应 ID 是几的结果行,读一页必须找到页头开始的行然后沿着它的 next 遍历到页尾,这件事还不能用 SQL 解决,得在代码里循环,数据库负担就很重了 不过,可以在这个基础上往外加上「桶」来映射排好序的样子可以解决。桶始终保持有序,如果你愿意也可以保持它的 capacity 平均,这样分页 offset 的时候估算会快(准)一些。然后读出的时候只需要检索桶 ID 符合的记录就可以了,与平时基本无异。 当需要分页和 offset 的时候,先提取桶表的 capacity 列来估计,比如一个桶容量是 100 ,我要 OFFSET 到 1000 ,那就先把前 10 个桶的 capacity 全读出来看够不够,当桶容量总体比较平均的时候这个估计是很近似的,要检索的量也很少。然后还是 where bucket_id in []就行 然后桶还可以嵌套,更小粒度的桶可以被大桶索引,而且对更下层的桶来说都无需改动原有的查询流程,迁移负担很小  —— 没错 恭喜我们又重新发明了 B+树 |
|
27
documentzhangx66 2022-03-19 02:59:07 +08:00
@GeruzoniAnsasu 我写的最后一段,文字太长,没排好版,导致你没注意看清楚...
|
|
28
GeruzoniAnsasu 2022-03-19 03:19:50 +08:00
@documentzhangx66 你再仔细想想,「重排序」的时候你想喂给数据库的是什么?
|
|
29
documentzhangx66 2022-03-19 04:56:04 +08:00
@GeruzoniAnsasu
我 27 楼评论的意思是,你在 26 楼评论我之前,需要认真看看我在 22 楼的评论的最后一段文字,因为那段文字里,有这样的一句话:“基于 链表与静态数组 的高级复合型数据结构”。这句话其实涵盖了几乎所有的数据结构,包括你在 26 楼写的结构。 另外重排序,并没有你在 28 楼里写的喂给数据库的这种说法。现代数据库的结构,也并不是你在 26 楼说的这么简单,其存储结构、内存结构、专用的排序区域与策略等等,比教科书中纯粹的 B+树要复杂很多。教科书为了教学,只会教最简单的东西。 |
 |
30
yzbythesea 2022-03-19 05:03:00 +08:00
|
|
31
GeruzoniAnsasu 2022-03-19 05:12:51 +08:00
@documentzhangx66
我是想说无论数据库怎样实现它的索引,在这个业务里并不能用得上。 SQL 并没有移动行然后自动给你更新所有自增列的值这种内建操作。 OP 描述的困境是,用于排序的索引值是稠密无缝的(如果 int 的话)。如果索引是随机访问地址,那么改变顺序就要批量更新大量地址,如果索引是相对地址(即链表),那没有任何现存机制帮助我们随机提取一批相邻索引的行。 数据库自己的数据结构 works perfect so what? how does it help? |
|
32
documentzhangx66 2022-03-19 05:19:31 +08:00
@yzbythesea
1.我写的是:基于 链表与静态数组 的高级复合型数据结构,不是 单纯的 链表或静态数组。这种高级复合型数据结构,几乎可以组成所有的数据结构,包括各种树、森林、网、环等等。你说的 BTree 已经包含在我说的里面。BTree 这种说法不严谨,准确来说是 B-Tree 或 B+Tree 。 2. Mysql 主流引擎,使用的结构有好几种,从 B-Tree 、B+Tree 、R-Tree 、Hash 结构,都有;而且 B-Tree 与 B+Tree 还存在争议。 |
|
33
documentzhangx66 2022-03-19 05:29:19 +08:00
@GeruzoniAnsasu
1.我在 22 楼写的那玩意,是在告诉楼主,静态数组 与 链表,在操作上的一些差异。 我并不是说,SQL 或 数据库引擎,就是这么运行的。 所以我在 22 楼结尾加了那段很长的文字,是在告诉楼主,现代数据库,比较复杂,让他别担心这个问题。 2.如果楼主关心的不是这事,而是关心数据库主流 B+Tree 结构,是怎么插入一个中间数值的,那么楼主可以去搜 B+Tree 的算法动画,看看分步演示。 3.数据库自己的数据结构,但并不一定 works perfect 。因为数据库并不知道用户的需求。所以近代数据库才有各种细分,比如关系型、NOSQL 、图数据库,等等。而且各种数据库懂优化的 DBA 贼贵。 |
|
34
GeruzoniAnsasu 2022-03-19 05:38:49 +08:00
我们往表里放了一个链表,现在插入和移动都变得很快了,这很好——
但我怎么知道第四个元素应该是 ID 为几的行? 看起来 ID=4 被 ID=5 指着,然后 ID=4 自己指着 ID=3…… 那,id=3/4/5 这三行到底是第几个元素?没有映射,他们的 ID 与 next/prev 都不直接反应呈现顺序。当只有一个表的时候这做不到。 所以需要第二个映射表。 第四个元素,按桶大小为 3 估计(我给的例子),应该在第二桶,那么我们 查 SUM(桶容量) WHERE ID <2 ,得到 3 , 再查 capacity WHERE id=2 ,为 3 ,说明确实在第二个桶里。那么 直接查第一个表 WHERE bucket_id = 2 ,提取出 3 行,看 2 号桶的头,是 id=2 。遍历内存里的三个元素找到 id=2 然后沿着 next 遍历(4-3)-1=0 次,得到 id=2 的元素。 总计 3 次查询完成了随机检索,一次桶表扫描,一次桶表索引,一次数据表索引,内存遍历忽略不计 |
|
35
GeruzoniAnsasu 2022-03-19 05:45:29 +08:00
@documentzhangx66
你甚至不知道 OP 遇到了个什么问题…… 他之前的做法可以 SELECT * ORDER BY pos ,pos 是个浮点,他可以在任意两个 pos 之间找一个数作为新 pos 。但这也许会有问题,所以他想问有没有不用浮点数的方案。 那如果不用浮点的话 没法指定 pos=1 和 pos=2 之间的新数了,想把 pos=100w 移到 1 和 2 中间让它变成 2 ,其它的顺次后移,怎么办? id=100w 的那行,pos 改成什么? pos=2 的那行 pos 改成什么?其它的呢? 好,如果不用这种 pos=整数的表示方法,我们用一个链表 —— 回到我的回复开头 |
|
36
documentzhangx66 2022-03-19 06:01:40 +08:00
|
|
37
GeruzoniAnsasu 2022-03-19 06:04:40 +08:00
@documentzhangx66 我在#28 是让你想清楚「直接操作」怎么操作,操作什么?是指真的去更新 100w 行吗?
|
|
38
yzbythesea 2022-03-19 06:07:16 +08:00
|
|
39
documentzhangx66 2022-03-19 06:13:42 +08:00
@GeruzoniAnsasu
1.直接操作具体是指怎么操作,需要楼主先讲清楚他的细节。包括设计细节与代码细节。 2.但无论怎么操作,只要他是正经的设计,不是乱来的设计,那么这个问题,原则上就是我在 22 楼给他科普的那些东西,不需要更新所有 100w 行。 3.我一直觉得,楼主是不是在设计上,犯了强制给表加一个 int 自增列的陋习,才带来这个额外的麻烦。1 楼也是看不懂楼主的操作,才提问。楼主在 4 楼,确认了 3 楼的回答正确;但 3 楼发言正确的前提,是建立在赞成楼主的设计。我觉得楼主的设计不一定正确,所以和 1 楼产生了同样的疑问。 |
|
40
documentzhangx66 2022-03-19 06:23:13 +08:00
@yzbythesea
你有这方面的误解,并不一定是你的问题。 国内的教课书与各种中文资料,比较古老与死板,它可能认为 链表、单链表、双链表,甚至动态数组、树、环,等等,都是不同的东西。 但如果你能够多翻翻国外的现代书籍,多翻翻英文版维基百科,多动手写写这些东西,自己多实现几遍,你会发现现代的理念有些不一样: 静态数组 与 链表,是组成高级数据结构的基石。 比如你觉得树和链表,不一样,但你想想,简单的树,是不是由链表衍生而来的?简单的环是不是链表首位相连?一些高级的树,是不是 链表上加了一些链表与静态数组? |
|
41
xylophone21 2022-03-19 10:00:41 +08:00
@GeruzoniAnsasu
其实还是需求没说清楚,原贴的需求是插入,34 楼你增加了要按 index/顺序取数据的需求。所以我们要原谅产品经理老改需求:) 但问题是 op 原贴的浮点数方案也不能按 index 取数据,你要第三个,排序号是 3 的,前面可能有 1.1, 1.11,1.111.....n 个,哪怕范围也不一定可靠,除非你的数据有其它特征,比如每天插入的数量有限,大概率均匀分布等。然后再利用每天晚上重新索引等办法解决。 所以多想一步,只能假设没有这个需求。 |
 |
42
wangritian 2022-03-19 10:04:59 +08:00
使用过类似楼主的方案,仍然保持整数,让运营设置的时候序号间隔为 10 ,如 10 20 30 ... -10 -20 -30 ... 方便后期插入
|
 |
43
rrfeng 2022-03-19 10:10:56 +08:00 via Android
现实中不可能有这种产品设计的。
真要做的话 score 预留间隔,移动的时候先计算有没有间隔有的话就直接更新,没有就移动周围临近的数据腾出空间。 为了保证空间足够可以用文本编码来做 score ,留个一万间隔怎么也够用了 |
 |
44
kosmosr 2022-03-19 10:20:13 +08:00 via Android
你的业务会取出 100w 条数据来?
|
 |
45
lililqth 2022-03-19 10:31:01 +08:00
没问题,这就类似于分布式系统中的 hybrid clock
|
 |
46
CokeMine 2022-03-19 10:41:27 +08:00 via Android |
 |
47
gjquoiai 2022-03-19 11:31:03 +08:00 @documentzhangx66 你完全没懂 @GeruzoniAnsasu 在说什么,甚至也没搞明白前提。前提是这坨数据已经在数据库里了,跟数据库用什么数据结构存一点关系也没有。你的做法是在数据库上实现链表,他的做法是在上面实现 B 树。所以就很清楚了,就是找个合适的数据结构在数据库上用表实现,你再想想链表合适吗?
|
 |
48
ganbuliao 2022-03-19 15:07:01 +08:00
直接换位不好吗
|
|
49
documentzhangx66 2022-03-19 16:20:19 +08:00
|
|
50
gjquoiai 2022-03-19 18:05:13 +08:00
@documentzhangx66 #49 OP 要解决的问题是很清楚的,只是提出一种设计方案不知道好不好。那么请问您的方案就是在数据库里存链表吗?
|
 |
51
wa007 2022-03-19 18:44:10 +08:00
盲猜有序链表
|
|
52
documentzhangx66 2022-03-19 21:51:25 +08:00
@gjquoiai
1.我不觉得楼主已经说清楚事情了,当然也许是我的理解能力有问题。不过既然有别人也提出这个疑问了,我觉得有必要请楼主仔细说说最原始的需求,以及楼主具体的设计与实现方案。 2.我在之前与别人的评论里,提出的方案是,如果楼主的设计没有乱来,那么楼主不需要关心这个事情,直接操作就行。但如果楼主在设计上出错,那么大家有必要了解楼主的原始需求是什么,因为有可能这是个 X-Y 问题。 |
 |
53
mmdsun 2022-03-19 22:27:10 +08:00 via iPhone
像微信表情那样排序,只给一个置顶操作。不要给自由拖动排序。或者给个上 /下按钮,update 加 /减数据 sort_num 字段即可。
|
 |
54
ch2 2022-03-19 23:43:57 +08:00
100W 大列表排序,前端是怎么展示的?
|
 |
55
twing37 2022-03-20 00:01:58 +08:00
@ch2 前端 lazylist render + sub bucket subscribe update 我现在就在做这件事
@GeruzoniAnsasu 我觉得这位兄弟的概括重新发明了 b 树这段话是明白人 op 应该把场景提出来. 比如: 榜单的实时排序 或者是 在线成员列表 这种场景下的解决方案而不是倒推 就好像大家疑惑的.那 100w 索引挪到位置 1 .这什么骚操作 |
 |
56
jie123168 2022-03-20 11:59:34 +08:00
我觉得楼主整体思路是没问题的:
加一个排序字段 priority. 修改该字段值来排序. 但是字段用浮点数不太合适. priority 最好用 int 或者 bigint. 而且 priority 不能连续生成.最好是有间隔比如默认是间隔 1000 或者 10000, 这样中间插入就方便了. 当相邻大小的两个 priority 数值差小于 2(中间不能再插入了)时. 要对附近的一批数据修改, 确保中间还能再插入. (这步操作可以异步的完成) |
 |
57
ClorisYe 2022-03-20 20:49:45 +08:00
想想这么大量的数据,有没有任意排的必要先。
|
 |
58
agostop 2022-03-20 22:32:40 +08:00
我觉得应该召唤一下 OP ,问问到底有没有分页展示的需求
按理说,@documentzhangx66 说用链表,是没问题,关键是不知道是否输出的时候需要分页展示? @GeruzoniAnsasu 意思就是如果你用链表,如果需要分页的情况下,就比较难办 |