
这是一个创建于 1320 天前的主题,其中的信息可能已经有所发展或是发生改变。
概述
跨服务更新数据是应用开发常见的任务,如果一些关键数据对一致性的要求较高,而业务上也不需要支持回滚的话,那么通常就会采用本地消息表的方式来保证最终一致。许多公司在处理跨服务更新数据一致性问题时,都会先引入本地消息表,后续随着业务场景复杂化,再引入更多的事务模式
本文提出的二阶消息,是一种新模式,新架构,优雅的解决了消息最终一致性的问题。解决同样的一个问题,可以将本地消息表或者事务消息中,上百行的代码简化为大约五六行,大大简化了架构,提升开发效率,具备非常大的优势。
下面我们以跨行转账作为例子,给大家详解这种新架构。业务场景介绍如下:
我们需要跨行从 A 转给 B 30 元,我们先进行可能失败的转出操作 TransOut ,即进行 A 扣减 30 元。如果 A 因余额不足扣减失败,那么转账直接失败,返回错误;如果扣减成功,那么进行下一步转入操作,因为转入操作没有余额不足的问题,可以假定转入操作一定会成功。
采用新架构开发
新架构基于分布式事务管理器 dtm-labs/dtm
完成上述任务的核心代码如下所示:
msg := dtmcli.NewMsg(DtmServer, gid).
Add(busi.Busi+"/TransIn", &TransReq{Amount: 30})
err := msg.DoAndSubmitDB(busi.Busi+"/QueryPreparedB", db, func(tx *sql.Tx) error {
return busi.SagaAdjustBalance(tx, busi.TransOutUID, -req.Amount, "SUCCESS")
})
上述代码是 HTTP 接入,gRPC 的接入和 HTTP 基本一样,这里不再赘述,有需要的读者,可以参考dtm-labs/dtm-examples中的例子
这部分代码中
- 首先生成一个 DTM 的 msg 全局事务,传递 dtm 的服务器地址和全局事务 id
- 给 msg 添加一个分支业务逻辑,这里的业务逻辑为余额转入操作 TransIn ,然后带上这个服务需要传递的数据,金额 30 元
-
然后调用 msg 的 DoAndSubmitDB ,这个函数保证业务成功执行和 msg 全局事务提交,要么同时成功,要么同时失败
- 第一个参数为回查 URL ,详细含义稍后说
- 第二个参数为 sql.DB ,是业务访问的数据库对象
- 第三个参数是业务函数,我们这个例子中的业务是给 A 扣减 30 元余额
由于当前 TransOut 业务操作与 TransIn 不再同一个服务,因此可能发生执行完一个操作后,发生进程 crash ,导致另一个操作未执行,此时 dtm 会通过回查 URL ,查询 TransOut 的业务操作是否成功完成。dtm 里面的回查只需要粘贴如下代码即可,框架会自动完成回查逻辑:
app.GET(BusiAPI+"/QueryPreparedB", dtmutil.WrapHandler2(func(c *gin.Context) interface{} {
return MustBarrierFromGin(c).QueryPrepared(dbGet())
}))
至此一个完整的二阶段消息的业务完成,接入复杂度、代码量比本地消息表等现有方案,都有巨大的优势,已成为这类问题的首选方案。您可以通过以下命令运行一个完整的例子:
运行 dtm
git clone https://github.com/dtm-labs/dtm && cd dtm
go run main.go
运行例子
git clone https://github.com/dtm-labs/dtm-examples && cd dtm-examples
go run main.go http_msg_doAndCommit
成功流程
DoAndSubmitDB 是如何保证业务成功执行与 msg 提交的原子性的呢?请看如下的时序图:
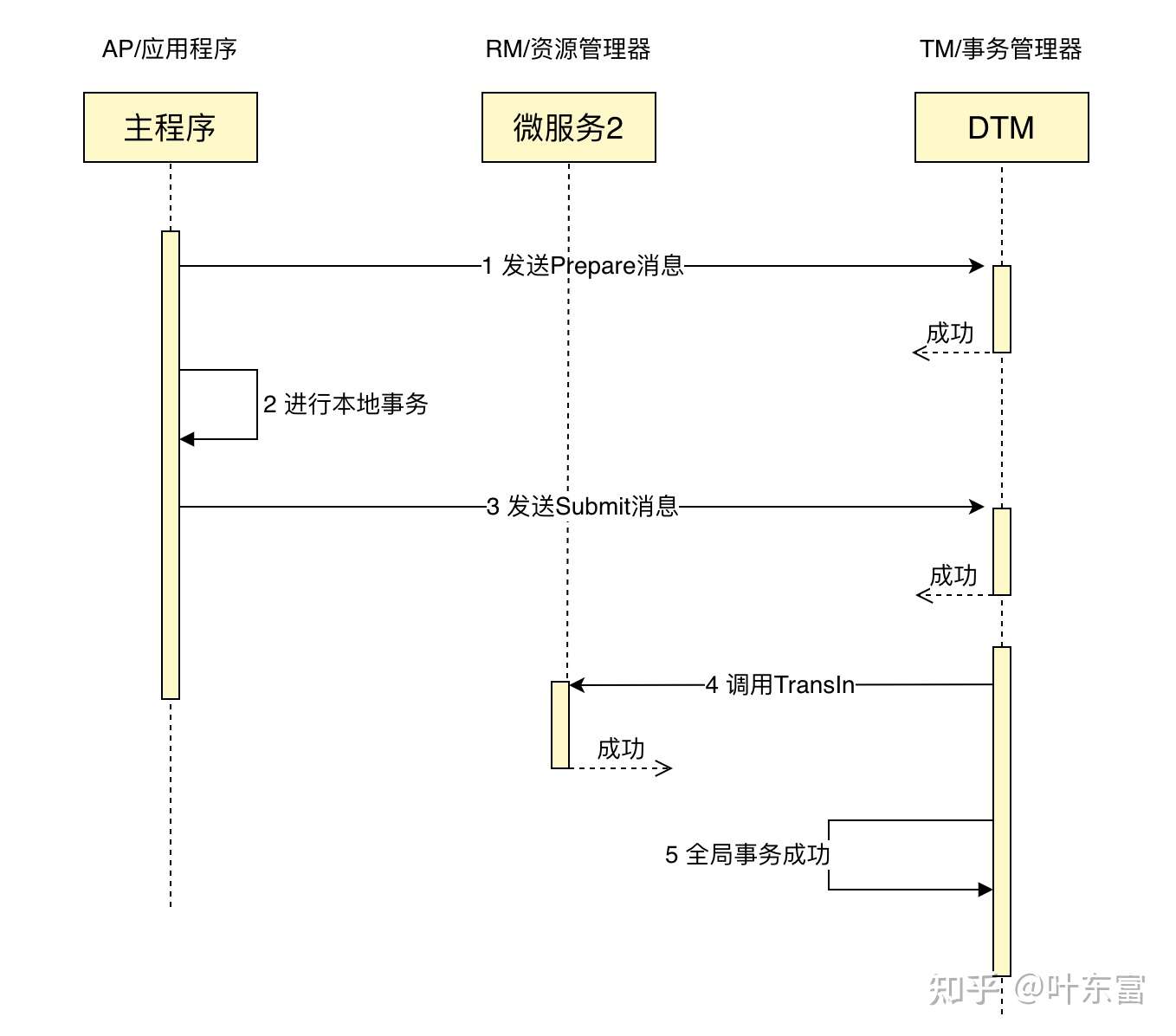
一般情况下,时序图中的 5 个步骤会正常完成,整个业务按照预期进行,全局事务完成。这里面有个新的内容需要解释一下,就是 msg 的提交是按照两个阶段发起的,第一阶段调用 Prepare ,第二阶段调用 Commit ,DTM 收到 Prepare 调用后,不会调用分支事务,而是等待后续的 Submit 。只有收到了 Submit ,开始分支调用,最终完成全局事务。
提交后宕机流程
在分布式系统中,各类的宕机和网络异常都是需要考虑的,下面我们来看看可能发生的问题:
首先我们要达到的最重要目标是业务成功执行和 msg 事务是原子操作,因此首先看如果在业务完成提交后,发送 Submit 消息前出现了宕机故障会怎么样,新架构如何保证原子性?
我们来看看这种情况下的时序图:
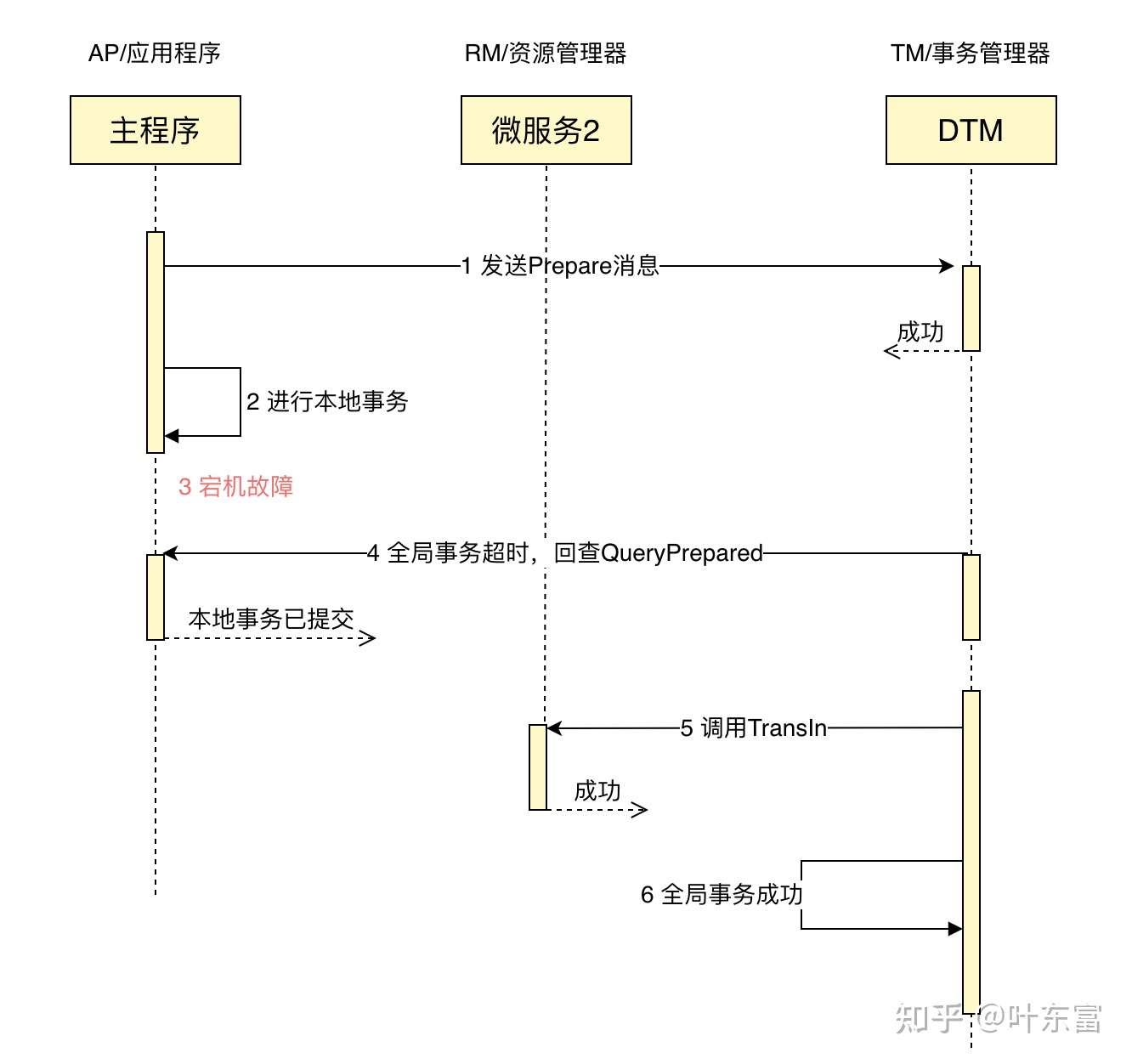
如果在本地事务提交之后,在发送 Submit 前,出现了进程 Crash 或者机器宕机会怎么样?这个时候 DTM 会在一定超时时间之后,取出只 Prepare 但未 Submit 的 msg 事务,调用 msg 事务指定的回查服务。
您的回查服务逻辑,不需要手动编写,只需要按照之前给出的代码进行调用即可,它会到表里面查询,本地事务是否提交了:
- 已提交: 返回成功,dtm 进行下一步子事务调用
- 已回滚: 返回失败,dtm 终止全局事务,不再进行子事务调用
- 进行中: 这个回查会等待最终结果,然后按照前面的已提交 /已回滚的情况处理
提交前宕机流程
我们来看看本地事务被回滚的时序图:
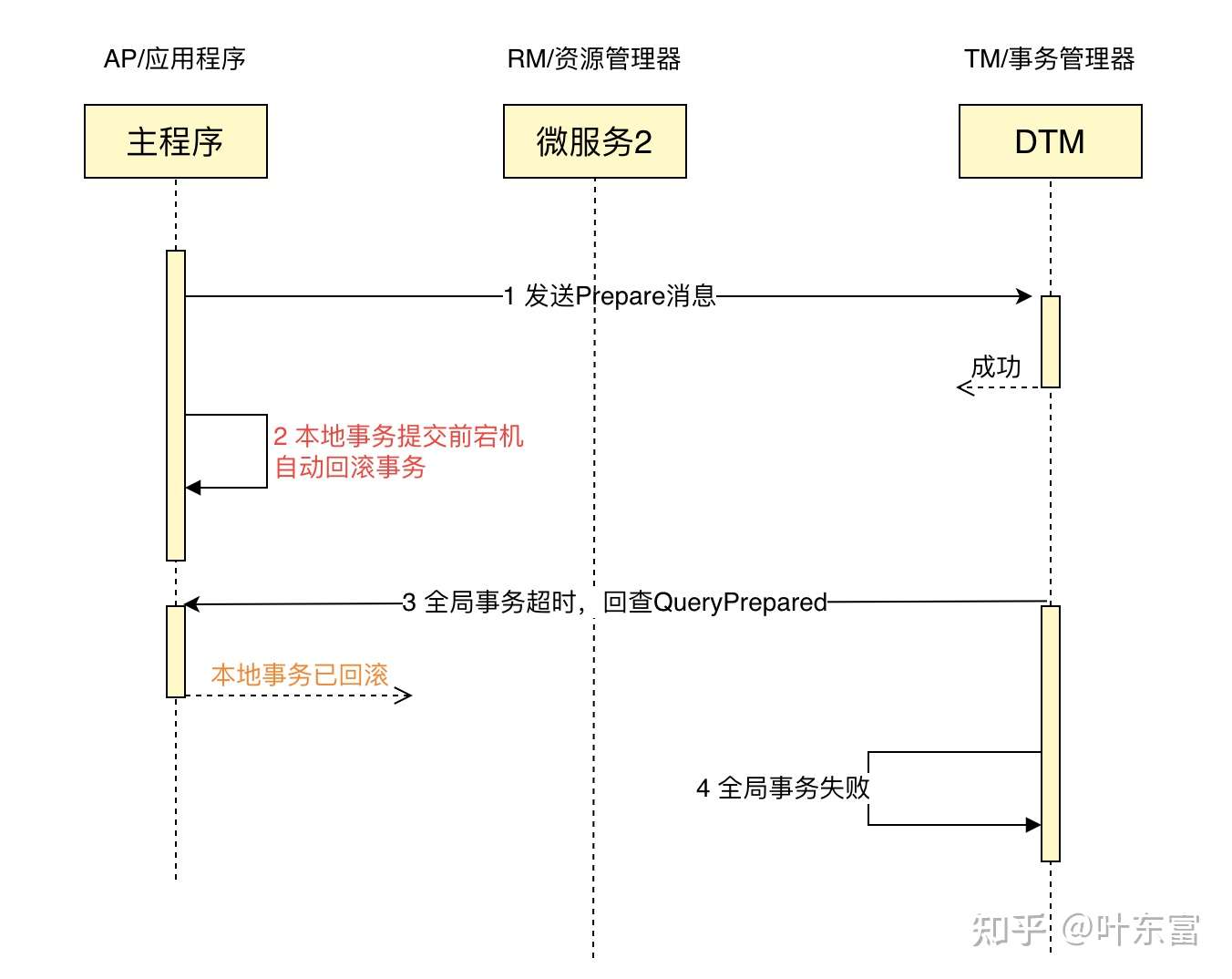
如果在 dtm 收到 Prepare 调用后,AP 在事务提交前,遇见故障宕机,那么数据库会检测到 AP 的连接断开,自动回滚本地事务。
后续 dtm 轮询取出已经超时的,只 Prepare 但没有 Submit 的全局事务,进行回查。回查服务发现本地事务已回滚,返回结果给 dtm 。dtm 收到已回滚的结果后,将全局事务标记为失败,并结束该全局事务。
易用性
采用新架构处理一致性问题,仅需要:
- 定义好本地业务逻辑,指定下一步处理的服务即可
- 定义 QueryPrepared 处理服务,复制粘贴例子代码即可。
然后我们看看其他方案情况
二阶消息 vs 本地消息表
上述的问题也可以采用本地消息表方案(方案详情参考分布式事务最经典的七种解决方案),来保证数据的最终一致性。如果采用本地消息表,需要的工作包括:
- 在本地事务中执行本地业务逻辑,将消息插入消息表并最后提交
- 编写轮询任务,将本地消息表的消息,发给消息队列
- 消费消息,并将消息发给相应的处理服务
两者对比,二阶消息有以下优点:
- 无需学习或维护任何消息队列
- 不需要处理轮询任务
- 不需要消费消息
二阶消息 vs 事务消息
上述的问题也可以采用 RocketMQ 的事务消息方案(方案详情参考分布式事务最经典的七种解决方案),来保证数据的最终一致性。如果采用本地消息表,需要的工作包括:
如果采用事务消息,需要的工作包括:
- 开启本地事务,发送半消息,提交事务,发送 commit 消息
- 消费超时的半消息,对于收到的超时半消息,查询本地数据库,然后进行 Commit/Rollback
- 消费已提交的消息,并将消息发送给处理服务
两者对比,二阶消息有以下优点:
- 无需学习或维护任何消息队列
- 本地事务与发送消息之间的复杂操作需要手动处理,一不小心,可能出现 bug 。而二阶消息则是全自动处理
- 不需要消费消息
二阶消息在二阶段提交方面,与 RocketMQ 的事务消息相似,是受到 RocketMQ 的事务消息启发后提出的新架构。二阶消息的命名,不再复用 RocketMQ 的事务消息,主要是因为二阶消息在架构上有很大的改变,而另一方面,在分布式事务的上下文中,使用”事务消息“这个名字,容易带来理解上的混淆。
更多的优点
对比于前面讲述的队列方案,二阶消息还有很多额外的优点:
- 二阶消息整个暴露的接口,完全与队列无关,只跟实际的业务和服务调用相关,对开发人员更加友好
- 二阶消息不用考虑消息队列消息堆积及其他故障等问题,因为二阶消息只依赖 dtm ,开发人员可以认为 dtm 与系统中其他一个普通无状态服务一样,只依赖背后的存储 Mysql/Redis 。
- 消息队列是异步的,而二阶消息同时支持异步和同步,默认异步,只需要打开 msg.WaitResult=true ,那么可以同步等待下游服务完成
- 二阶消息还支持同时指定多个下游服务
二阶消息未来展望
二阶消息能够大幅降低消息最终一致性解决方案的难度,获得广泛的应用。未来 dtm 会考虑添加后台,允许动态指定下游服务,提供更高的灵活性。如果您原先采用消息队列来做服务解耦,那么这个 dtm 的后台,允许你直接指定某个消息的多个接收函数,无需编写消息消费者,带来更加简单、直观、易用的开发体验。
回查原理剖析
前面的时序图中,以及接口中都出现了回查服务,在二阶消息中,是复制粘贴代码自动处理的,而 RocketMQ 的事务消息,则是手动处理的。那么自动处理的原理是什么?
要进行回查,首先要在业务数据库实例中,建立一张独立的表,里面保存全局事务 id 。在处理业务事务时,会把 gid 写入到这张表。
当我们用 gid 回查时,如果能够在表中查到 gid ,那么说明本地事务已提交,这样就可以返回 dtm ,告知本地事务已提交。
当我们用 gid 回查时,没有在表中查到 gid ,那么说明本地事务未提交,此时可能的结果是两个,一是事务还在进行中,二是事务已回滚。我查了许多关于 RocketMQ 的资料,未找到有效的解决方案。搜到所有解决方案是,如果未查到结果,那么什么都不做,等待下一次回查,如果 2 分钟或者更久的回查,一直都是查不到的,那么认为本地事务已回滚。
上述这种方案有很大的问题:
- 两分钟还查不到 gid ,并不能认为本地事务已回滚,极端情况下,可能发生数据库故障(例如进程或磁盘卡住了),持续时间超过 2 分钟,最后数据又提交了,那么这个时候,数据就不是最终一致了,就需要人工介入处理了
- 如果一个本地事务,已经回滚了,但是回查操作,还会在两分钟之内,按照 10s 左右的时间间隔,不断的进行轮询,会给服务器造成不必要的压力
而 dtm 的二阶消息方案,则彻底解决了这部分的问题。dtm 的二阶消息工作过程如下:
- 在处理本地事务时,会将 gid 插入到 dtm_barrier.barrier 表中,同时带上插入原因为 committed 。该表有一个唯一索引,主要字段为 gid 。
- 当进行回查时,二阶消息的操作不是直接查 gid 是否存在,而是再 insert ignore 一条带有相同 gid 的数据,同时带上插入原因为 rollbacked 。此时如果表中如果已有 gid 的记录,那么新的插入操作就会被 ignore ,否则数据会被插入。
- 然后再用 gid 查询表中的记录,如果查到记录的 reason 为 committed ,那么说明本地事务已提交;如果查到记录的 reason 为 rollbacked ,那么说明本地事务已回滚。
那么对比 RocketMQ 回查时的常见方案,二阶消息是如何区分出进行中和已回滚呢?其中的技巧在于回查时插入的数据,如果回查时,数据库的事务还在进行中,那么插入操作就会被进行中的事务阻塞,因为插入操作会等待事务中持有的锁。如果插入操作正常返回,那么数据库中的本地事务,必定已结束,必然是已提交或已回滚。
下面给大家留一个问题:二阶消息的操作 3 能否省略,能否只根据步骤 2 的插入是否成功,来判断是否已回滚?欢迎大家留言讨论
普通消息
二阶消息不仅可以替换本地消息表方案,也能够替换普通消息方案。如果直接调用 Submit ,那么就与普通消息方案近似,但是提供了更灵活简单的接口。
假设一个这样的应用场景,界面上有一个参加活动的按钮,如果参加活动,会赠与两本电子书的永久权限。这种情况下,可以再这个按钮的服务端中,类似这样处理:
msg := dtmcli.NewMsg(DtmServer, gid).
Add(busi.Busi+"/AuthBook", &Req{UID: 1, BookID: 5}).
Add(busi.Busi+"/AuthBook", &Req{UID: 1, BookID: 6})
err := msg.Submit()
这种方式也提供了异步接口,而不用依赖消息消息队列。在微服务的许多场景中,可以替换原有的异步消息架构。
小结
本文提出的二阶消息,接口简洁优雅,带来了比本地消息表和 Rocket 事务消息更简单的架构,可以帮助大家更好的解决无需回滚的数据一致性问题。
项目地址
关于分布式事务更多的理论知识与实践,可以访问以下项目和公众号:
https://github.com/dtm-labs/dtm ,欢迎访问,并 star 支持我们。
关注 [分布式事务] 公众号,获取更多分布式事务相关知识,同时可以加入我们的社群
第 1 条附言 · 2022-04-06 10:07:27 +08:00
dtm 项目目前 5K+ star ,已在腾讯,字节等大厂线上部署使用,大家可以放心使用
 |
1
leon0318 2022-04-06 09:56:39 +08:00 via iPhone 翻到最后一定有广告,果不其然……
|
 |
2
dongfuye1 OP 主要内容都是干货哈,当然也希望将好架构好的项目推给大家,让更多人了解使用
|
 |
3
putaozhenhaochi 2022-04-06 10:23:39 +08:00 via Android 革谁的命
|
|
4
dongfuye1 OP @putaozhenhaochi 新的架构可以完美替代本地消息表和事务消息
|
 |
5
stop9125 2022-04-06 11:03:34 +08:00
请教下,有部分没有看懂,如果按照这么做,那处理事务的压力全部都在 DTM 上,那 DTM 不就演变成一个单点服务了么,那处理瓶颈很明显啊,而且他的稳定性你是怎么保障的呢
|
|
6
dongfuye1 OP @stop9125 DTM 本身是无状态的,会将全局事务的进度保存在数据库或者 Redis 中。这种架构可以直接部署多实例,提供高可用的服务。
|
 |
7
metrue 2022-04-06 11:19:31 +08:00 测试的覆盖率这么低,企业都敢用,也是心大.
|
 |
9
zagfai 2022-04-06 11:38:07 +08:00 年轻人总想着搞点大事情出来,
|
|
10
dongfuye1 OP @metrue 不好意思,测试覆盖率一直是在 95%+,参见 https://app.codecov.io/gh/dtm-labs/dtm ,这几天可能 codecov 有变更导致一下子变成了 17%,预计今天会修复这个问题
正在使用的企业已经包括了腾讯,字节,可以放心使用的 |
 |
11
Chinsung 2022-04-06 12:01:18 +08:00
这个和 RocketMQ 支持的事务消息有什么区别吗
|
 |
14
swulling 2022-04-06 12:11:08 +08:00
客观评价一下哈:
分布式事务多数公司都是自己实现,三方库 Java 有一些,其他语言很少。这个项目补上了一个空缺。 但是项目的定位比较尴尬,如果是公司的核心业务,一般不会用三方库实现分布式事务,自己实现的难度也不高。所以多数是中小业务会使用来提升开发速度。 从具体的使用案例上看,哪怕是腾讯字节也一般用在非核心业务上。 |
|
15
dongfuye1 OP @Chinsung 文中有介绍跟 RocketMQ 的事务消息的区别。从时序图上面看,两者比较接近,文中也说了这个方案受到事务消息的启发。不同点在于:1. 自动回查的处理,RocketMQ 的消息回查方案,全网搜到的,都是有问题的,而 dtm 解决了这个问题,还申请了专利; 2. dtm 暴露给用户的,全部是 api 式的接口,与消息队列无关,用户无需掌握消息队列的知识,也无需维护一个高可用的消息队列,最终代码也大幅度简化,因此开发维护成本大幅降低
|
|
16
dongfuye1 OP @swulling dtm 在腾讯内部已经使用很广泛,承担的负载也比较高,有多个事业部在使用。给 dtm 提 PR 的腾讯同学,已经有了六七位了。
自己实现分布式事务的难度一点都不小哈,了解过字节百度他们内部也有分布式事务项目,他们是有专门的小组负责,在一定的范围内适用。 即使大厂自己实现的分布式事务,也不一定比开源做得更好。许多对分布式事务有过研究的大厂同学同事,对 dtm 的认可度非常高 |
|
17
swulling 2022-04-06 12:28:23 +08:00 via iPhone
|
|
18
dongfuye1 OP @swulling 腾讯的微信支付当然没有使用 dtm 哈,dtm 开源还不到一年的时间。
dtm 合并了六七位腾讯同学提过来 PR ,这个是确定的哈。至于具体什么业务什么部门用了 dtm ,未经过对方允许,我也不能够公开往外说 |
|
19
swulling 2022-04-06 12:47:12 +08:00
@dongfuye1
> 但是项目的定位比较尴尬,如果是公司的核心业务,一般不会用三方库实现分布式事务 那你说我这句话有啥问题?核心业务,比如腾讯的支付,阿里的支付,会用 dtm 实现么?不仅现在不可能,可见的未来也不可能。 更多的是一些非核心的业务,比如一些内部的计算平台或者某些业务流程需要加事务之类的。 |
|
20
Chinsung 2022-04-06 13:53:03 +08:00
@dongfuye1 #15 所以我其实好奇哈,事务性消息之所以叫做半消息,就是因为它具有消息该有的特性,那你的 dtm 在通知下游微服务 2 的时候,能保证最终一致性吗?重试策略和拉取策略是什么?
并且解耦方面也存在问题,就比如比较常见的电商场景,加入支付成功操作要扣减库存和减少优惠券,我定义了 TranIn1 和 TranIn2 ,这个时候我又要给用户加积分了,我是不是要在 TranOut 端定义 TranIn3 ?另一个问题就是,你如何保证这种广播式事务的情况下,dtm 的“推”性能? 上面这些问题也都是消息队列中间件解决了的问题,dtm 是否都需要从新解决一次 |
|
21
stop9125 2022-04-06 14:31:31 +08:00
@dongfuye1 那还是一个中心化的服务,那出了问题如何容灾和恢复呢
我理解这是对资源的一种锁定,那再没有处理完之前是个什么状态呢,这样的话单个资源的并发是不是会很低 虽然是多实例,但是底层还是依赖 mysql ,这个数据库瓶颈是如何解决的 刚开始研究分布式事务,问题比较多,希望指正一下,感谢 |
 |
22
yzbythesea 2022-04-06 15:01:34 +08:00
不要动则就革那啥命啊。prepare - submit 模式早有了?我知道 dynamodb transcation 是基于这个实现的。
DTM 内部怎么实现也没讲,如果只靠 redis/mysql 保证稳定性那还是不行的。 |
|
23
dongfuye1 OP @stop9125 普通的应用一般都会把数据保存在共享的存储,例如 mysql 中,云厂商基本都提供了支持高可用的数据库服务,如果需要容灾,云厂商也会有相关的方案。
你说的这个资源锁定,我还不清楚具体指什么,如果说扣库存的场景,那么在数据库中扣库存,那么单个商品的并发上限并不高,但假如不是争抢一个商品项,那么 dtm 的性能测试中,普通配置可以达到 900+tps ,如果要更好的并发,可以选择 redis 存储,单个 redis 可以做到 1w+tps 。 如果您需要 mysql 存储更高的性能,当前可以部署多组,未来 dtm 可能会开发集群版,或者自定义的存储,支持更高的性能。 |
|
24
dongfuye1 OP @yzbythesea 文中没有说 prepare-submit 是二阶段消息的创新点,也说明了这种方式是受到了 RocketMQ 事务消息的启发。二阶段消息带来的主要变化是,大幅度简化了使用者的工作量,使用者完全只需要使用 api 的方式,不需要任何消息队列,就能够解决消息最终一致性的问题,大幅度减少代码量,大幅降低使用门槛。原理上,二阶段消息做了自动回查,这个是首创,还申请了专利。
现在 redis/mysql 都已经有主从复制,能够保证稳定性了,对于绝大多数的应用已经足够了哈 |
 |
25
A555 2022-04-06 15:08:32 +08:00
点进去发现已经 start 过了
|
|
26
dongfuye1 OP @Chinsung 通知下游微服务 2 的时候,如果中间出错,会进行重试,保证最终一致性。
解耦方面,如果又要给用户加积分,那么可以定义好了新的加积分服务之后,未来只需要在 dtm 的管理后台里面,针对这个消息类型,添加上新服务的配置就行,类似于新服务去消费支付成功的消息。 广播式的事务这种,对于正常未出错的请求,dtm 的性能消耗是非常低的,就是正常的记录全局事务进度。而对于出错需要重试的请求,代价也不高,就是批量查询出超时的全局事务,然后进行处理即可。 dtm 针对解决分布式事务中的问题,在这方面已比较完善。但定位不一样,不会把消息中间件的所有功能都支持 |
|
27
stop9125 2022-04-06 15:21:07 +08:00 @dongfuye1 感觉直接甩锅给云厂商是有问题的,就说明这个 sla 必然低于云厂商的 sla ,这在金融场景是不可接受的吧🤔
这个 tps 量级可能也用不到什么流量大的服务上,感觉场景有限。不过思路可以参考下。 |
|
28
yzbythesea 2022-04-06 15:25:56 +08:00
|
|
29
dongfuye1 OP @yzbythesea 谷歌分布式锁 Chubby 的公开数据显示,集群能提供 99.99958 %的平均可用性,一年也就 130s 的运行中断。还没有听说哪个厂以 6 个 9 作为标准了,一年只允许 13s 以内的不可用?
|
|
30
yzbythesea 2022-04-06 15:38:00 +08:00
@dongfuye1 谷歌云的 authentication ?你挂 1 秒就是所有服务都登不上去了。
|
|
31
dongfuye1 OP @yzbythesea 难道服务都不重试的吗?也没听说过哪个厂的服务挂了 1s 成为新闻的。无论是 lvs 这类高可用设施,还是现代的分布式共识算法,在出现机器宕机后,摘除正在使用故障机器,都不是 1s 完成的,通常都在 3s 以上
|
|
32
yzbythesea 2022-04-06 15:52:03 +08:00
|
|
33
dongfuye1 OP @yzbythesea 这个惊群问题是一个经典问题,跟重试并不是同一个问题,而是 epoll 相关的一个问题,已经有解决方案了。
|
 |
34
cassyfar 2022-04-06 16:02:13 +08:00
@dongfuye1 刚看了下谷歌云 IAM ( auth )的 SLA ,官方这是要默认 100%
https://cloud.google.com/iam/sla 惊群问题你想下十几秒攒的大量客户端都在不停重试,等于服务上线,请求已经远高于你预估峰值数倍,直接就击穿了。当然你可以用别的办法去缓解,但还是很麻烦。最好就是不要宕机。 |
|
35
dongfuye1 OP @cassyfar 没看出来这个是要默认 100%,而我更认为达到了 99.99958 %的平均可用性,那么用户已经不需要关心可用性问题了。
对于重试这个场景,都会有一个策略,一般都会延迟重试,并且有限流,去避免重试导致的负载问题。应用当然希望没有宕机,但是在分布式应用中,宕机是不可避免的,因此微服务框架、K8S 云原生都会有相应的策略,处理这样的情况。 |
 |
37
z960112559 2022-04-07 09:13:19 +08:00
看见项目里面乱七八糟的简写就不想用
|
|
38
dongfuye1 OP @z960112559 是否有具体一些的意见? Go 里面的命名一般都比 Java 短
|
 |
39
brust 2022-04-07 15:35:22 +08:00 支持下 OP
但是我个人比较讨厌在开源项目里面推广自己公众号等等的 |
|
40
brust 2022-04-07 16:46:05 +08:00
摸鱼的时候在看文档
文档写的还是不错的 |
 |
42
fkue587 2022-04-08 20:08:04 +08:00
@putaozhenhaochi 看标题我就想进来说这句话 后来 怕查水表 点进来一看 有大佬先说了
|
|
43
z960112559 2022-04-09 09:19:03 +08:00
@dongfuye1 cli svr 写全也多不了几个字符吧
|
 |
44
wolfmei 2022-04-09 09:39:06 +08:00
看了半天发现我这里不是这种架构
|
|
45
dongfuye1 OP @z960112559 这种简写含义已经很明显了,缩写不会造成歧义。在没有大的歧义的情况下,那么采用缩写或者不缩写,就只是不同语言,不同开发者的风格喜好不同了,并无好坏之分
|
 |
46
seakingii 2022-04-14 16:36:07 +08:00
很讨厌公众号,最后里面一定是无数的广告
|
 |
47
kongkongyzt 2022-04-19 08:45:35 +08:00
这个是不是在 go-zero 上有介绍过?感觉眼熟
|
|
48
dongfuye1 OP @kongkongyzt 是的,go-zero 是微服务框架,dtm 则解决单体事务拆分后无法保持 acid 的问题
|
 |
49
1018ji 2022-04-24 16:17:59 +08:00
2 只能是本地事务吗?
|
|
50
dongfuye1 OP @1018ji 2 只能是本地事务,可以是 redis sql mongodb 。如果是服务的话,那么就变成普通的 msg 或者 saga 了
|
 |
51
xhinliang 2022-04-25 10:35:41 +08:00
我就想看看大家怎么喷你。
|
 |
52
Y29tL2gwd2Fy 2022-04-26 19:37:02 +08:00
字长不看
|
 |
53
pkupyx 2022-05-07 00:03:44 +08:00
看起来还挺好的,为啥评论怪怪的,就不能夸夸吗。
我觉得只要数据一致性可靠,服务 sla 并不是那么重要。 |
 |
54
leeUp 2022-05-07 09:45:43 +08:00
支持楼主~
|
 |
55
tairan2006 2022-05-08 14:53:02 +08:00 via Android
挺好的 支持
|
 |
56
fatyoung 2022-05-10 14:16:07 +08:00
谢谢分享
|