
开源了 VectorHub,用文件和网页进行 GPT Embedding,并且能够分享给他人使用,发挥你创意的时候到了!
ligz · 2023-07-13 09:22:29 +08:00 · 3083 次点击这是一个创建于 608 天前的主题,其中的信息可能已经有所发展或是发生改变。

目前已实现的功能:
- 通过上传文件 GPT embedding
- 通过输入网页 URL 进行 GPT embedding
- 创建 vector 数据,后续可以多次使用
- 直接使用他人创建好的 vector 数据
- 100% 代码开源
我在今年四月的时候,开源了 ChatFile 项目,收获了 2.4K 的 stars, 该项目的目的是上传文件进行 GPT 的 Embedding ,能够上传 PDF 、Epub 、Markdown 、Text 、Zip 等等一些系列格式的文件做到 ChatPDF 之类的效果。
新的项目设计的初衷是,ChatFiles 在之前开源后,收到了很多用户的上传文件使用 Embedding ,但是这些 Embedding 并不能被所有人重复使用,这样就形成了大量的浪费,大家都在给 OpenAI 交重复的钱💰。
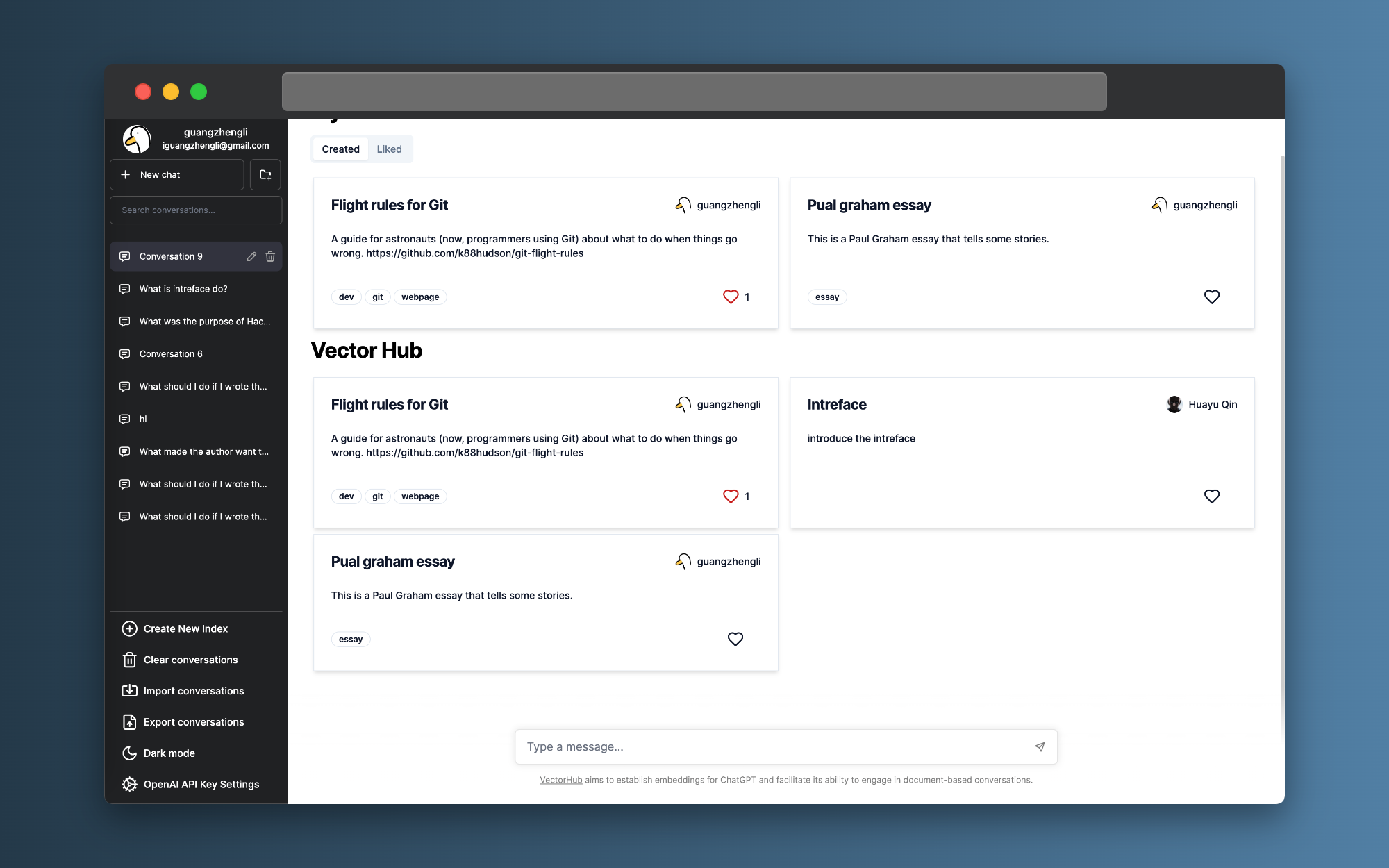
例如我在 https://chat.vectorhub.org 中 Embedding 了 https://github.com/k88hudson/git-flight-rules/blob/master/README.md 的材料。
并提供了一些快速的开始问题,那么其它用户就不需要再次花钱 embedding 就可以使用该数据。
大家也可以想一想还有什么有趣的可以进行 embedding 的。可以用你的 API Key embedding 然后所有人一起使用。也可以在这个帖子讨论,后续项目的进展在 我的推特 上更新。
目前项目还在初期,大家可以多多提提 bug 。新的项目地址: https://github.com/guangzhengli/vectorhub
 |
1
ql562482472 2023-07-13 09:41:27 +08:00
请问一下是不是可以理解为在模型的上下文上添加了一些资料?在我们的对话中可以有更详尽的参考?还是添加了一种新的思维方式啊,或者是一些 prompt ?主要是不明白这是个啥 所以想请教一下
|
 |
2
SWALLOWW 2023-07-13 09:50:34 +08:00
我也没懂,能不能举例一个使用场景
|
 |
3
zzh161 2023-07-13 09:53:19 +08:00
翻了半天,这个怎么设置代理?一定要代理本机所有流量?
|
 |
4
Seanfuck 2023-07-13 09:54:04 +08:00
问题是每个人用的文件或网页不同,这个不同于模型能通用
|
 |
5
hyperzlib 2023-07-13 10:10:46 +08:00
顺便提一嘴,如果要本地搭建、低成本向量搜索,也可以试试 BERT 的 Embedding 。
|
 |
6
ligz OP @SWALLOWW
@ql562482472 @SWALLOWW @ql562482472 举个例子,我基于 https://github.com/k88hudson/git-flight-rules/blob/master/README.md 这个 Git 操作手册进行 Embedding 创建了 vector 数据后,就可以问 ChatGPT 基于这个文档材料相关的问题。例如问 I want to undo rebase/merge ,它就会回复 To undo a rebase or merge, you can reset your branch to the original HEAD pointer using the ORIG_HEAD variable. Use the command "git reset --hard ORIG_HEAD" to recover your branch to its state before the rebase/merge. 这段话是基于材料的上下文,而不是 GPT 的自由发挥。 再比如我上传朱自清的《背影》这篇文章,我问橘子是谁买的?可以得到回复是父亲买的。 所以这个功能是基于上传材料的上下文得到 GPT 的回答,而不是纯粹的 GPT 问答。 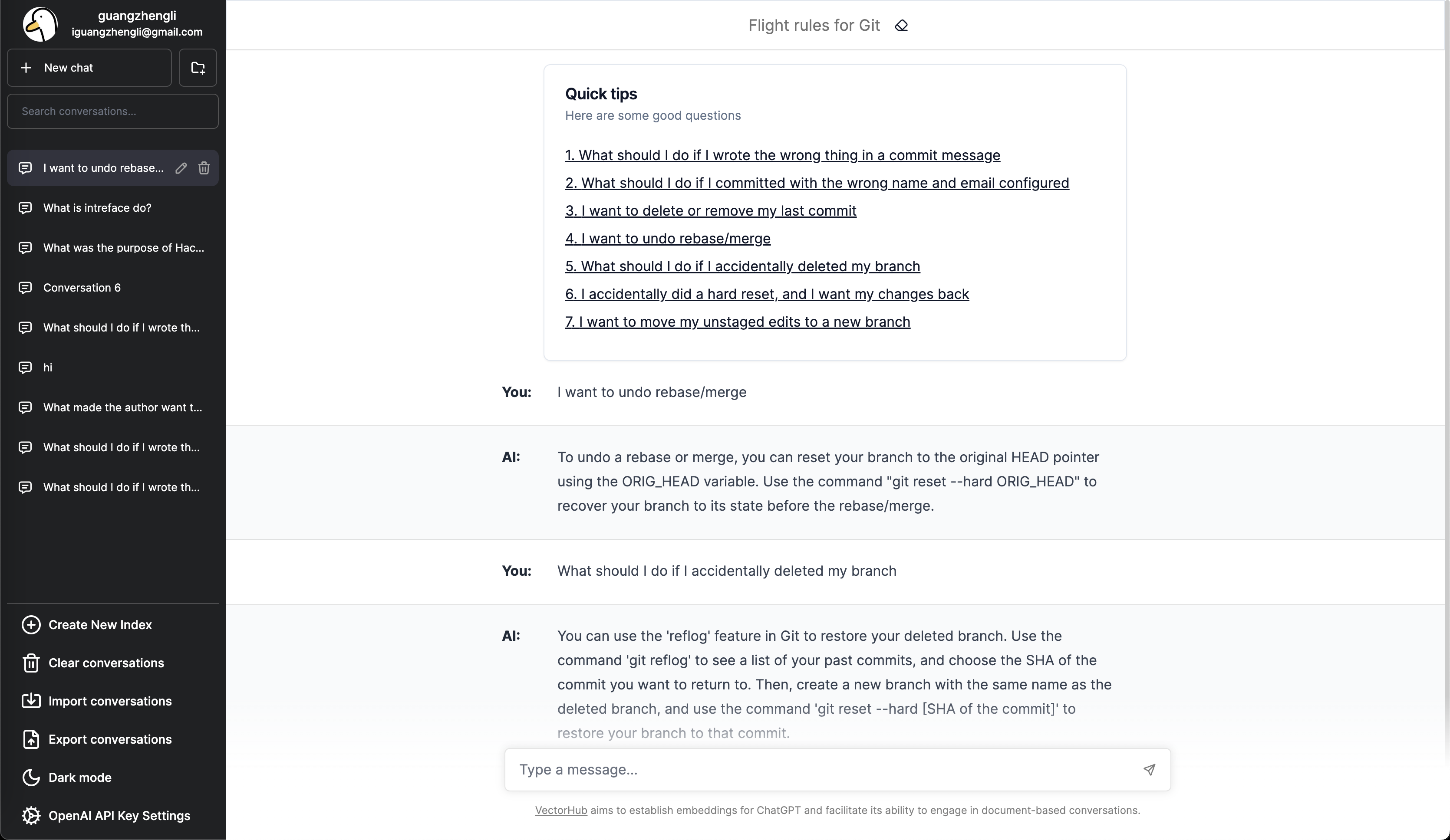 |
 |
10
pkoukk 2023-07-13 11:29:55 +08:00
langchain 好用么?
|
|
12
ligz OP @pkoukk #10 LangChain 还是可以的,这个项目所有和 OpenAI / Azure Openai 集成的代码都是用的 LangChain ,想要学习 LangChain 写 AI 应用的小伙伴可以拉代码看看。
如果不想用 Python 写 AI 应用,我觉得 LangChainJs 是唯一选择。 |
 |
13
mMartin 2023-07-13 11:49:56 +08:00
这不就知识库么
|
 |
14
hahastudio 2023-07-13 13:22:12 +08:00
关于 embedding 能否共享,我觉得大不了再存一个 model 名字就好了,顶多就是同一段文字有好几个 vector 结果,相当于是大型缓存
但有几个问题: 1. 可能同一篇文章不同的应用切出来的片不一样,有潜在浪费 2. 需要假定传上来的都是可以放在公有领域的文字,不然别人付费了 paywall 做了 embedding 然后我没花钱也能拿到结果? |
 |
15
easychen 2023-07-13 13:34:39 +08:00 我也觉得这块可以搞搞,还注册了 vechub.cn 😂 感觉还是给 embedding 定义一个开放格式,然后分享这个格式的文件比较好。这样各种聊天客户端可以直接支持,用户只需要去下载文件导入就能直接使用。
|
 |
16
connectsixboy 2023-07-13 14:42:27 +08:00
获取的 embedding 短时间内可以用,但是 OpenAI 更新模型之后,之前的获取的 embedding 是不是就失效了啊?
|
|
17
ligz OP @hahastudio embedding 共享的商业化我也感觉有点难,感觉细分领域自己创建独有业务领域的 embedding 数据给别人使用还是很有前景的
|
|
18
ligz OP @connectsixboy 理论上模型变化很大会造成失效,但是 OpenAI 最近都是更新 gpt 模型,text-embedding 模型更新频率很慢。
|
 |
19
flyingfz 2023-07-13 15:36:04 +08:00
建议要加上 **模型** 类型。
相信大部分人,由于各种原因,应该是没办法调用 open ai 的接口的, 替代的方案,可以自己部署类似 BERT 或者 text2vec 的各种模型。 |
 |
20
rpman 2023-07-13 15:39:16 +08:00
如何区分不同的 chunking 方式?
|
 |
21
EthanLiu1993 2023-07-13 16:36:33 +08:00 厉害,很早之前就关注了 chatFile ,晚上回去再看看这个
|